Go Pointers and Error Handling for Python Developers
Pointers and Error Handling: The Two Things That Trip Up Every Python Developer
We've spent the last section talking about Go's obsession with being explicit — your types tell the compiler and other developers exactly what you're building toward. Interfaces enforce this at compile time. Now we're going to look at the two concepts that really require you to retrain your brain: pointers and error handling.
Here's the thing: they're not quirks or annoying relics of systems programming. They're deliberate design choices that make your code more predictable. And in production, predictability is worth its weight in gold.
Let's start with pointers. The confusion there is mostly conceptual — nobody's neurons naturally fire in the direction of memory addresses without practice. But here's what should reassure you: you've been working with references in Python all along. You just never had to think about it.
Error handling is more of a habits adjustment. Python encourages exceptions; Go encourages explicit error returns. They're both aiming for the same destination (reliable code), but Go takes a much clearer path to get there, and once you're building web services that handle thousands of requests per second, that clarity becomes essential.
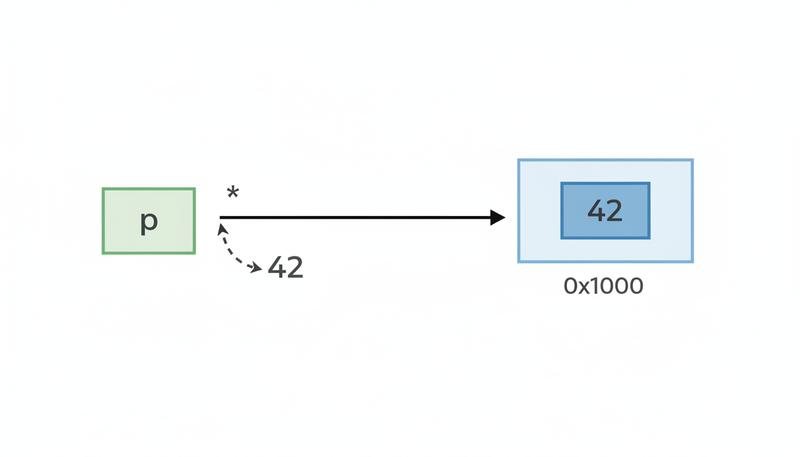
When You Actually Need a Pointer
There are three concrete situations where you reach for pointers in Go, and understanding these will save you hours of confusion:
1. Modifying a value inside a function
This is the gotcha that trips up almost every Python developer at first. In Python, if you pass a mutable object like a list to a function, the function can modify it. If you pass an int, it can't — ints are immutable. In Go, the default is much stricter: nothing gets modified unless you explicitly opt in with a pointer.
// This does NOT work — the function gets a copy
func doubleWrong(n int) {
n = n * 2 // modifies the copy, not the original
}
// This DOES work — the function gets a pointer to the original
func doubleRight(n *int) {
*n = *n * 2 // modifies the value at the address
}
func main() {
x := 5
doubleWrong(x)
fmt.Println(x) // still 5
doubleRight(&x)
fmt.Println(x) // 10 ✓
}
The & operator gives you the address of a variable. The * operator dereferences it — it says "go fetch the value at this address." It's a small syntactic thing, but it makes the intent unmistakable. When you see doubleRight(&x), you're announcing to everyone reading the code: "I'm letting this function modify x." No surprises, no invisible side effects.
2. Avoiding expensive copies of large structs
If you have a struct with dozens of fields, copying it on every function call is wasteful. Your CPU cycles get spent copying memory around when you could just pass the address (typically 8 bytes on a 64-bit system), no matter how big the original struct is.
type BigStruct struct {
Name string
Scores [1000]float64
// ... many more fields
}
// Efficient: passes a pointer, not a copy of the whole struct
func process(b *BigStruct) {
fmt.Println(b.Name)
}
3. Sharing state across goroutines (with proper synchronization)
When multiple goroutines need to work with the same data, they need to reference the same memory location — which means pointers. We'll dig deep into this in the concurrency section, but this is where pointers become genuinely essential for building real services.
Pointer Receivers on Methods
You'll see this pattern everywhere in Go web code:
type Server struct {
host string
port int
}
// Pointer receiver — can modify the struct
func (s *Server) setPort(port int) {
s.port = port
}
// Value receiver — gets a copy, can't modify the original
func (s Server) address() string {
return fmt.Sprintf("%s:%d", s.host, s.port)
}
The practical rule: if a method needs to modify the struct, or if the struct is large, use a pointer receiver (*Server). If neither applies, you technically can use a value receiver — but the Go style guides generally recommend picking one approach and being consistent across all methods of a type. Don't mix and match.
The Python Reference Model vs. Go's Explicit Pointer Model
This is where the mental model really diverges. Let me lay out the difference:
graph LR
subgraph Python
A[Variable] -->|always a reference| B[Object on heap]
C[Function arg] -->|same reference| B
end
subgraph Go
D[Variable] -->|stores value directly| E[Value]
F[Pointer] -->|stores address| E
G[Function arg] -->|copy of value by default| H[New copy]
I[Pointer arg] -->|copy of address| E
end
In Python, variables are names that point to objects — everything's a reference, and you don't think about it. In Go, variables hold values directly. Stack allocation is common for small values. When you want reference semantics, you reach for a pointer explicitly. This is the trade-off in action: Go gives you control over memory layout and makes data flow obvious, but you occasionally have to type & and *.
Remember: Go's default is pass-by-value. If you're used to Python's "objects are always references" model, you'll need to consciously remember this, especially with structs. Passing a struct without
&means the function gets its own copy.
nil Pointers: Go's Most Common Runtime Panic
Every Go developer has a story. You write what you think is correct code, run it, and boom: runtime error: invalid memory address or nil pointer dereference. A nil pointer is a pointer that doesn't point anywhere — it's the Go equivalent of Python's None. Dereference it, and you crash:
var p *int // p is nil — a pointer with no address
fmt.Println(*p) // PANIC: you just tried to access memory that doesn't exist
This is Go's version of Python's AttributeError: 'NoneType' object has no attribute '...' — except in Go it crashes the program instead of raising an exception. The fix is always the same: check before you dereference.
func safeDereference(p *int) {
if p == nil {
fmt.Println("pointer is nil, nothing to do")
return
}
fmt.Println(*p)
}
In web service code, you'll often use pointers for optional fields in structs — a nil pointer can mean "not set" or "not provided." The discipline is: whenever you have a pointer, ask yourself whether it could be nil, and handle that case. Don't just assume it's always valid.
Warning: A nil pointer panic in a web handler will crash the goroutine handling that request. If you're not recovering from panics, it could take down the whole server. Always check for nil before dereferencing pointers that come from external sources — request parsing, database results, configuration files, API responses.
Error Handling: A Different Philosophy, Not a Missing Feature
Now we get to the topic that generates the most passionate debates in Go forums. Python uses exceptions. You raise them, you catch them, and the stack automatically unwinds. Go is fundamentally different: functions return errors as regular values, and the caller decides what to do about them. Explicit, every time.
Here's what the same operation looks like in both languages:
# Python
try:
with open("config.json", "r") as f:
data = json.load(f)
except FileNotFoundError:
print("Config file not found")
except json.JSONDecodeError as e:
print(f"Invalid JSON: {e}")
// Go
data, err := os.ReadFile("config.json")
if err != nil {
fmt.Println("Config file not found or unreadable:", err)
return
}
var config Config
if err := json.Unmarshal(data, &config); err != nil {
fmt.Println("Invalid JSON:", err)
return
}
Yes, Go is more verbose. That's intentional. But look at what you get in exchange: every error handling decision is explicit and right there in the code. You can see exactly which operations can fail, and exactly how the caller responds. There's no implicit stack unwinding, no wondering "where did this exception actually come from?", no accidentally swallowing errors because your except clause was too broad.
The Go FAQ addresses this directly. The language designers believed that exceptions mix control flow with error handling in ways that make code harder to reason about. When you're running a service handling thousands of concurrent requests, that reasoning clarity becomes invaluable.
The error Interface
In Go, error is just an interface:
type error interface {
Error() string
}
Anything with an Error() string method is an error. This means you can create custom error types with as much context as you need:
type ValidationError struct {
Field string
Message string
}
func (e *ValidationError) Error() string {
return fmt.Sprintf("validation failed on field %q: %s", e.Field, e.Message)
}
// This now satisfies the error interface
func validateAge(age int) error {
if age < 0 {
return &ValidationError{Field: "age", Message: "must be non-negative"}
}
return nil
}
When nothing went wrong, you return nil. That's the Go convention: nil error means success.
The Idiomatic Pattern
You're going to write this exact sequence hundreds of times in a Go codebase. Get comfortable with it now:
result, err := someOperation()
if err != nil {
return fmt.Errorf("someOperation failed: %w", err)
}
// use result safely here
That if err != nil check is so pervasive it becomes muscle memory. Some people find it tedious. Most experienced Go developers find it reassuring — it forces you to think about failure modes at the exact point where they occur, not in a catch block somewhere else in the stack.
Tip: If you find yourself writing
if err != nil { return err }forty times in a single file and it's all following the same pattern, you haven't done anything wrong — that's Go working as designed. Don't fight it. If you have complex error transformation logic, extract it into a helper function. But don't reach for external libraries that try to replicate exception behavior. They fight the language, and the language will win.
Creating Errors: errors.New and fmt.Errorf
The standard library gives you two straightforward tools:
import (
"errors"
"fmt"
)
// Simple error with a message
err1 := errors.New("something went wrong")
// Error with formatted context
userID := 42
err2 := fmt.Errorf("user %d not found", userID)
// Error wrapping — preserves the original error for inspection
originalErr := errors.New("connection refused")
wrapped := fmt.Errorf("failed to connect to database: %w", originalErr)
That %w verb is the important one. It wraps the original error, meaning callers can inspect what actually happened underneath. This is Go's version of Python's raise NewError from original_error. Without the %w, you're just creating a new error that contains the original's text as a string, and the original is lost forever.
Checking Error Types: errors.Is and errors.As
When you wrap errors, you need a way to check whether a specific error type is hiding somewhere in the chain. That's what errors.Is and errors.As do:
var ErrNotFound = errors.New("not found")
func findUser(id int) error {
// simulate a not found condition
return fmt.Errorf("findUser: %w", ErrNotFound)
}
func main() {
err := findUser(99)
// errors.Is checks if ErrNotFound is anywhere in the error chain
if errors.Is(err, ErrNotFound) {
fmt.Println("User doesn't exist — 404 territory")
}
}
errors.As is for when you want to extract a specific error type (like your custom struct) from the chain:
err := validateAge(-5)
var valErr *ValidationError
if errors.As(err, &valErr) {
fmt.Printf("Field %q is invalid: %s\n", valErr.Field, valErr.Message)
}
graph TD
A[Function returns error] --> B{Is error nil?}
B -->|Yes| C[Success — use the result]
B -->|No| D{What kind of error?}
D -->|errors.Is check| E[Known sentinel error]
D -->|errors.As check| F[Custom error type with fields]
D -->|Neither| G[Unknown error — log and return]
E --> H[Handle specifically]
F --> I[Extract fields and handle]
The Python equivalent would be using isinstance(exc, MyCustomError) inside an except block. errors.As is essentially the same thing, just written in Go's style.
Sentinel Errors: Go's Version of Specific Exception Types
In Python, you might catch ValueError or KeyError. In Go, you define sentinel errors — package-level error variables that represent specific failure conditions:
package store
var (
ErrNotFound = errors.New("not found")
ErrDuplicate = errors.New("duplicate entry")
ErrForbidden = errors.New("forbidden")
)
func (s *Store) GetUser(id int) (*User, error) {
user, ok := s.users[id]
if !ok {
return nil, ErrNotFound
}
return user, nil
}
Callers can then use errors.Is(err, store.ErrNotFound) to handle specific cases — deciding whether to return a 404 versus a 500 HTTP response. This is how the standard library itself works: io.EOF, os.ErrNotExist, sql.ErrNoRows are all sentinel errors you check with errors.Is.
The Error Handling Pattern in a Web Handler
Here's what this looks like in practice — the kind of code you'll actually write when we build out the REST API later:
func (h *Handler) GetUser(w http.ResponseWriter, r *http.Request) {
idStr := r.URL.Query().Get("id")
id, err := strconv.Atoi(idStr)
if err != nil {
http.Error(w, "invalid user id", http.StatusBadRequest)
return
}
user, err := h.store.GetUser(id)
if errors.Is(err, store.ErrNotFound) {
http.Error(w, "user not found", http.StatusNotFound)
return
}
if err != nil {
// Unexpected error — log it and return 500
log.Printf("GetUser: unexpected error: %v", err)
http.Error(w, "internal server error", http.StatusInternalServerError)
return
}
json.NewEncoder(w).Encode(user)
}
Notice the pattern: specific errors get specific HTTP responses, unexpected errors get logged and return 500. The structure is explicit and testable. Every path through the function is visible. You can't accidentally swallow an error by writing too broad a catch clause, because you're forced to deal with each one explicitly.
When to Use panic and recover (Almost Never)
Go does have a panic mechanism. When you panic, the program starts unwinding the stack, running any deferred functions along the way, and eventually crashes (or gets caught by recover). It looks superficially like raising an exception.
The Go community's strong consensus: panic is for programming errors and truly unrecoverable situations, not for normal error handling. If you're panicking over a failed database query, you've made a mistake.
// Legitimate use of panic — a bug, not an expected error
func mustPositive(n int) int {
if n <= 0 {
panic(fmt.Sprintf("mustPositive called with non-positive value: %d", n))
}
return n
}
// NOT legitimate — never do this
func getUser(id int) *User {
user, err := db.FindUser(id)
if err != nil {
panic(err) // ❌ Don't do this
}
return user
}
recover lets you catch a panic — but it only works inside a deferred function:
func safeOperation() (err error) {
defer func() {
if r := recover(); r != nil {
err = fmt.Errorf("recovered from panic: %v", r)
}
}()
// ... code that might panic
return nil
}
The legitimate use of recover in web services is a top-level middleware that catches panics in handlers and converts them into 500 responses instead of crashing the server. Most web frameworks including Gin include this by default. Beyond that defensive safety net, if you find yourself reaching for panic/recover as a control flow mechanism, stop — you're drifting back toward Python's exception model, and the idiomatic Go solution is to return an error instead.
Warning: A panic in a goroutine that doesn't recover will crash the entire program, not just that goroutine. This is very different from Python, where an uncaught exception in a thread doesn't necessarily kill the process. In Go, an unrecovered panic propagates up and terminates the application. In a web service, this means one panicking handler can take down your entire server.
defer: Cleanup Code the Go Way
defer is Go's mechanism for running cleanup code when a function exits — no matter how it exits (normal return, early return, or panic). Python handles this with with statements and context managers. They solve the same problem, just differently.
func processFile(filename string) error {
f, err := os.Open(filename)
if err != nil {
return fmt.Errorf("opening file: %w", err)
}
defer f.Close() // runs when processFile returns, no matter what
// ... do work with f
return nil
}
The Python equivalent:
def process_file(filename: str) -> None:
with open(filename) as f:
# do work with f
pass # f.close() called automatically
Both ensure cleanup happens. The difference is that defer is more flexible. You can defer multiple things, and they execute in LIFO order — last deferred runs first:
func multiCleanup() {
defer fmt.Println("third — runs first")
defer fmt.Println("second — runs second")
defer fmt.Println("first — runs last")
// Output order: first, second, third — reversed
}
This LIFO behavior is deliberate. If you acquire resources A, then B, then C, you want to release them in reverse order (C, B, A). defer handles this automatically.
In web services, defer is commonly used like this:
func (h *Handler) CreateOrder(w http.ResponseWriter, r *http.Request) {
// Start a database transaction
tx, err := h.db.Begin()
if err != nil {
http.Error(w, "database error", http.StatusInternalServerError)
return
}
// Defer rollback — if we return early due to error, this cleans up
// If we commit successfully, the rollback is a no-op
defer tx.Rollback()
// ... do work, potentially returning early on error ...
if err := tx.Commit(); err != nil {
http.Error(w, "commit failed", http.StatusInternalServerError)
return
}
w.WriteHeader(http.StatusCreated)
}
One important caveat: deferred functions capture variables by reference. This can produce surprising results if you're not careful. The Go by Example guide on defer covers these edge cases and is worth bookmarking.
Putting It Together: A Realistic Example
Here's a mini service function that combines pointers, error handling, and defer in a realistic way — something you'd actually write when building the REST API we're heading toward:
type UserService struct {
db *sql.DB
}
func (s *UserService) UpdateEmail(userID int, newEmail string) error {
// Validate — using a sentinel error pattern
if newEmail == "" {
return errors.New("email cannot be empty")
}
tx, err := s.db.Begin()
if err != nil {
return fmt.Errorf("UpdateEmail: begin transaction: %w", err)
}
defer tx.Rollback() // cleanup on any early return
// Query returns a pointer — could be nil if not found
var user User
err = tx.QueryRow("SELECT id, email FROM users WHERE id = $1", userID).
Scan(&user.ID, &user.Email)
if errors.Is(err, sql.ErrNoRows) {
return fmt.Errorf("UpdateEmail: %w", store.ErrNotFound)
}
if err != nil {
return fmt.Errorf("UpdateEmail: query user: %w", err)
}
_, err = tx.Exec("UPDATE users SET email = $1 WHERE id = $2", newEmail, userID)
if err != nil {
return fmt.Errorf("UpdateEmail: exec update: %w", err)
}
if err := tx.Commit(); err != nil {
return fmt.Errorf("UpdateEmail: commit: %w", err)
}
return nil
}
Read through this. Every error is explicitly handled. Every potential failure point is visible. Cleanup is guaranteed by defer. The function signature tells you exactly what can go wrong — it returns an error. No hidden control flow, no exception hierarchy to memorize. This is Go's philosophy about error handling in practice: verbose by design, nothing hiding.
What You Give Up and What You Get
Coming from Python, you do lose something. The verbosity of if err != nil is real. You can't write a function five lines long without dealing with error handling if anything in it can fail. There's no implicit exception propagation — if you forget to check an error, nothing happens, which can lead to silent failures if you're not careful. The freecodecamp Go handbook covers the mechanics, but the real shift is philosophical.
What you gain is equally real: every function's failure modes are explicit in its signature, errors can't accidentally propagate three layers up past a blanket catch Exception block, and reading any function's code tells you exactly where things can fail. In a large codebase with a team, this matters enormously. In a web service where you're debugging a 2am incident, you really want this clarity.
The thesis of this course is that Go's trade-offs are intentional — you trade flexibility for predictability. Pointers and error handling are where that trade-off feels most visceral. The verbosity isn't a bug; it's the language insisting that you stay explicit. Once that clicks, most Python developers find they actually appreciate it — at least for the kind of reliable, high-throughput web services Go is built for.
Only visible to you
Sign in to take notes.