Classic Design Patterns in Pythonic Dress
There is a moment in every software team's life when someone says "we need a Strategy here" and everyone nods and gets to work—and a different moment when someone says "I wrote a thing that swaps out the algorithm at runtime" and everyone stares blankly for thirty seconds before asking what that means. The difference between those two conversations is vocabulary.
That is the first and most underappreciated gift of the Gang of Four patterns: not the class diagrams, not the UML, but the names. When your team shares a pattern vocabulary, design reviews take fifteen minutes instead of an hour. Architecture documents stop needing three diagrams to explain something that a single word would handle. The GoF catalog is, at its core, a shared dictionary for programmers who need to talk about recurring structural problems without reinventing the description every time.
That said, there is a trap. Pick up any early-2000s Java textbook on design patterns and you will find elaborate class hierarchies, abstract base classes four levels deep, and factories that produce factories. The patterns themselves are real—the forces they address are absolutely real—but the implementations are strangled by Java's constraints. Python does not have those constraints. Python has first-class functions, duck typing, decorators baked into the syntax, and a type system flexible enough to bend without breaking. When you reach for a pattern in Python, the idiomatic implementation is almost always simpler than the canonical Java version, sometimes dramatically so.
This section walks through the patterns most relevant to clean architecture—Adapter, Strategy, Observer, Factory, Decorator, and Template Method—showing how each one looks in idiomatic Python and being honest about when you actually need the full pattern versus when a simple function will do the job better.
The Adapter Pattern: Making the Outside World Speak Your Language
Every non-trivial Python application eventually talks to something it did not write: a third-party library, a legacy system, an external API, a database driver. Those things have their own interfaces, shaped by their own history and conventions, and those interfaces almost never match what your domain expects.
The Adapter pattern is the canonical answer to that mismatch. You write a thin wrapper that translates calls from your domain's interface into calls the third-party thing understands. Your core code never touches the third-party interface directly; it only talks to the adapter. This gives you three concrete benefits: your core code stays clean, swapping out the third-party becomes a single-file change, and testing becomes straightforward because you can substitute a fake adapter without touching production code.
Here is a concrete scenario. Suppose your domain has a concept of sending notifications. You define what a notifier looks like using a Protocol (covered in depth in Section 6, but the idea is simple—if it has a send method with the right signature, it qualifies):
from typing import Protocol
class Notifier(Protocol):
def send(self, recipient: str, subject: str, body: str) -> None:
...
Your domain code calls notifier.send(...) everywhere. It does not care whether that notification becomes an email, an SMS, a Slack message, or a log line. Now suppose you are using SendGrid for email. The SendGrid Python client has its own API:
import sendgrid
from sendgrid.helpers.mail import Mail
class SendGridAdapter:
def __init__(self, api_key: str, from_address: str) -> None:
self._client = sendgrid.SendGridAPIClient(api_key)
self._from = from_address
def send(self, recipient: str, subject: str, body: str) -> None:
message = Mail(
from_email=self._from,
to_emails=recipient,
subject=subject,
html_content=body,
)
self._client.send(message)
SendGridAdapter structurally satisfies the Notifier Protocol—same send method, same signature—without inheriting from anything. Your domain code never needs to change if you later swap SendGrid for Mailgun. The adapter absorbs the translation.
A few practitioner notes worth heeding. First, keep adapters thin. The moment your adapter contains logic beyond translation, you have a problem: now the adapter has two reasons to change (the external interface changes and the business logic changes), which violates single-responsibility. If there is real logic involved—rate limiting, retry, formatting—extract it into a separate layer or service that the adapter calls. Second, adapters make excellent seams for testing. In your test suite, drop in a FakeNotifier that records calls instead of sending email. You have never needed to mock sendgrid internals, which means your tests stay focused on your domain logic.
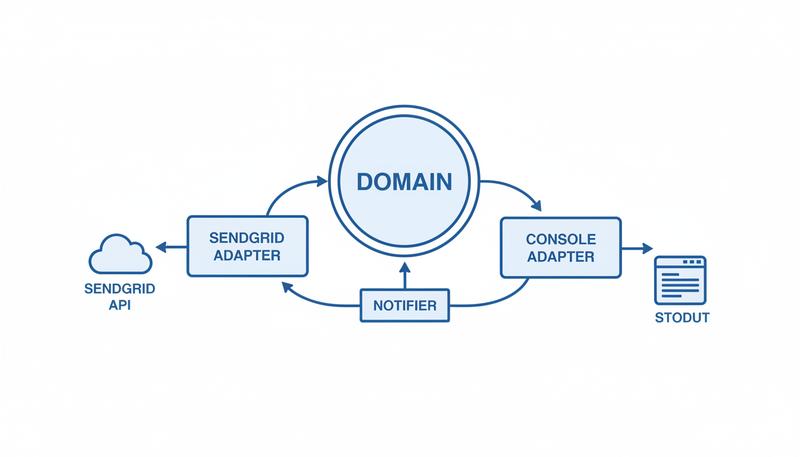
Adapter vs. Facade: A Distinction Worth Preserving
These two patterns get confused constantly, and the confusion has real costs downstream.
An Adapter has a specific job: make an existing interface look like a different interface. The interface you want to conform to already exists (your Notifier Protocol). The adapter makes the third-party thing conform to it.
A Facade has a different job: simplify a complex subsystem behind a single surface. The Facade does not adapt to a pre-existing interface; it creates a new, simpler interface over something complicated. If you have a payment library with seventeen classes and forty methods, you might write a PaymentFacade with three methods—charge, refund, void—that handles the orchestration internally.
graph LR
subgraph "Adapter"
A1[Your Domain] -->|calls Notifier Protocol| B1[SendGridAdapter]
B1 -->|translates to| C1[SendGrid SDK]
end
subgraph "Facade"
A2[Your Domain] -->|calls simple API| B2[PaymentFacade]
B2 -->|orchestrates| C2[Auth Service]
B2 -->|orchestrates| D2[Charge Service]
B2 -->|orchestrates| E2[Receipt Service]
end
The practical rule: if you are adapting to an interface your code already expects, that is an Adapter. If you are creating a simpler interface to hide complexity, that is a Facade. They can coexist—a Facade over a third-party library might itself be adapted to your domain's Protocol.
The Strategy Pattern: Replacing Conditionals with Pluggable Behaviour
Here is a smell you have seen a thousand times:
def calculate_shipping(order, method):
if method == "standard":
return order.weight * 0.05
elif method == "express":
return order.weight * 0.15 + 5.00
elif method == "overnight":
return order.weight * 0.25 + 15.00
else:
raise ValueError(f"Unknown method: {method}")
Every time someone wants a new shipping method, they modify this function. This is the Open-Closed Principle being violated in plain sight. The Strategy pattern says: extract each branch into its own object (or function), and pass the chosen strategy in from outside. The calculate_shipping function no longer needs to know how shipping is calculated—just that something knows.
The class-based implementation mirrors the GoF original and is appropriate when strategies need their own state or configuration:
from typing import Protocol
from dataclasses import dataclass
@dataclass
class Order:
weight: float
class ShippingStrategy(Protocol):
def calculate(self, order: Order) -> float:
...
class StandardShipping:
def calculate(self, order: Order) -> float:
return order.weight * 0.05
class ExpressShipping:
def __init__(self, surcharge: float = 5.00) -> None:
self.surcharge = surcharge
def calculate(self, order: Order) -> float:
return order.weight * 0.15 + self.surcharge
class OvernightShipping:
def calculate(self, order: Order) -> float:
return order.weight * 0.25 + 15.00
def calculate_shipping(order: Order, strategy: ShippingStrategy) -> float:
return strategy.calculate(order)
Now calculate_shipping is closed for modification and open for extension. Adding DroneShipping is a new file, not a change to existing code.
The function-based implementation is often better when strategies are stateless. Python functions are first-class objects. A callable is a callable.
from typing import Callable
ShippingStrategy = Callable[[Order], float]
def standard_shipping(order: Order) -> float:
return order.weight * 0.05
def express_shipping(order: Order) -> float:
return order.weight * 0.15 + 5.00
def calculate_shipping(order: Order, strategy: ShippingStrategy) -> float:
return strategy(order)
# Usage:
total = calculate_shipping(my_order, express_shipping)
Half the boilerplate, same isolation, same testability. You can even use functools.partial to bind configuration to a stateless function—overnight = functools.partial(express_shipping, surcharge=15.00)—which is the Python equivalent of a Strategy object with constructor arguments.
The rule of thumb: reach for the class-based Strategy when strategies carry state or when you want the type system to enforce the interface explicitly (a Protocol does this cleanly). Reach for callable Strategies when they are pure transformations. Do not write a class whose only job is to hold a single method and no state; that is a function masquerading as something more complicated.
The Observer Pattern: Decoupling Producers from Consumers
Your order is placed. Now what? An email needs to go out, the inventory needs updating, a Slack notification needs posting, and somewhere a business analyst's dashboard needs refreshing. If your place_order function calls all of these directly, you have a system where every new requirement means editing the order placement code. The Observer pattern exists precisely to break this coupling.
The pattern says: the producer (the subject or publisher) maintains a list of observers (or subscribers) and notifies them when something happens. The producer has no idea who the observers are or what they do. Observers register themselves.
from __future__ import annotations
from typing import Callable, Any
from dataclasses import dataclass, field
@dataclass
class Order:
order_id: str
customer_email: str
total: float
# A simple event bus
EventHandler = Callable[[Any], None]
class EventBus:
def __init__(self) -> None:
self._subscribers: dict[str, list[EventHandler]] = {}
def subscribe(self, event_type: str, handler: EventHandler) -> None:
self._subscribers.setdefault(event_type, []).append(handler)
def publish(self, event_type: str, payload: Any) -> None:
for handler in self._subscribers.get(event_type, []):
handler(payload)
bus = EventBus()
def send_confirmation_email(order: Order) -> None:
print(f"Email sent to {order.customer_email}")
def update_inventory(order: Order) -> None:
print(f"Inventory updated for order {order.order_id}")
bus.subscribe("order_placed", send_confirmation_email)
bus.subscribe("order_placed", update_inventory)
# In your order service:
def place_order(order: Order, events: EventBus) -> None:
# ... save to database, run business rules ...
events.publish("order_placed", order)
The place_order function knows nothing about email or inventory. It publishes an event; whoever cares can subscribe. Adding new behaviour—say, a fraud check triggered on order_placed—is a single subscribe call added somewhere at startup. No changes to place_order.
In production systems, this basic in-process event bus frequently evolves into something backed by a message queue (Celery, RQ, AWS EventBridge). The Observer pattern is the conceptual skeleton; the infrastructure varies. The key architectural benefit remains the same at every scale: the thing that produces the event does not depend on the things that consume it.
One honest warning: Observer patterns, especially in large systems, can make causality hard to trace. When your order_placed event triggers fifteen handlers spread across twelve files, debugging "why did X happen after Y" becomes an exercise in grep. Keep your event subscriptions centralised—one bootstrap location where all subscriptions are registered, not scattered across modules—and you will thank yourself later when you are trying to understand the chain of events.
Factory Method and Abstract Factory: Controlling Object Construction
Creation logic is behaviour, and behaviour that gets complicated deserves to be encapsulated. That is the insight behind the Factory patterns.
Factory Method solves the problem of "I know I need to create an object, but the exact class should be decided by a subclass or by configuration." Here is a direct Python example—a report generator that can produce different output formats:
from abc import ABC, abstractmethod
class Report(ABC):
@abstractmethod
def render(self, data: list[dict]) -> str:
...
class CSVReport(Report):
def render(self, data: list[dict]) -> str:
if not data:
return ""
headers = ",".join(data[0].keys())
rows = [",".join(str(v) for v in row.values()) for row in data]
return "\n".join([headers] + rows)
class JSONReport(Report):
def render(self, data: list[dict]) -> str:
import json
return json.dumps(data, indent=2)
def create_report(format: str) -> Report:
registry = {
"csv": CSVReport,
"json": JSONReport,
}
cls = registry.get(format)
if cls is None:
raise ValueError(f"Unknown report format: {format}")
return cls()
Notice that create_report is a plain function—not a class method on an abstract factory. In Python, this is usually sufficient. The GoF Factory Method involves subclassing a creator class, which adds weight that Python's first-class support for functions and classes often makes unnecessary. A dictionary mapping keys to classes, plus a creation function, achieves the same decoupling with much less ceremony.
Abstract Factory steps up a level: instead of creating one kind of object, it creates families of related objects that should be used together. Suppose you have a UI toolkit that needs to produce a consistent set of widgets for different platforms:
from typing import Protocol
class Button(Protocol):
def render(self) -> str: ...
class Checkbox(Protocol):
def render(self) -> str: ...
class UIFactory(Protocol):
def create_button(self) -> Button: ...
def create_checkbox(self) -> Checkbox: ...
# Dark theme implementation
class DarkButton:
def render(self) -> str:
return "<button class='dark'>Click</button>"
class DarkCheckbox:
def render(self) -> str:
return "<input type='checkbox' class='dark' />"
class DarkUIFactory:
def create_button(self) -> DarkButton:
return DarkButton()
def create_checkbox(self) -> DarkCheckbox:
return DarkCheckbox()
The key constraint Abstract Factory enforces: you get consistent families. If you ask a DarkUIFactory for widgets, you get dark widgets. You cannot accidentally mix a dark button with a light checkbox, because you only talk to one factory at a time.
In data engineering, you see Abstract Factory used to create families of readers and writers for different storage backends. In web frameworks, it shows up in test doubles—a TestingDatabaseFactory produces in-memory repositories, while a ProductionDatabaseFactory produces PostgreSQL-backed ones.
graph TD
A[Application Code] -->|uses| B[UIFactory Protocol]
B -->|implemented by| C[DarkUIFactory]
B -->|implemented by| D[LightUIFactory]
C -->|creates| E[DarkButton]
C -->|creates| F[DarkCheckbox]
D -->|creates| G[LightButton]
D -->|creates| H[LightCheckbox]
The Decorator Pattern: Adding Behaviour Without Subclassing
Here is where things get interesting, because Python has two things called "decorator" and they are related but distinct.
The Decorator pattern (GoF) says: wrap an object in another object that has the same interface, adding behaviour around the original. No subclassing required. The wrapping can be stacked—wrapper inside wrapper—giving you composable behaviour extension.
Python's @decorator syntax is a specific mechanism for applying functions that wrap other functions (or classes). It is inspired by the Decorator pattern but is not identical to it.
Let us take the pattern first. Suppose you have a DataSource interface:
class DataSource(Protocol):
def read(self) -> bytes: ...
def write(self, data: bytes) -> None: ...
class FileDataSource:
def __init__(self, path: str) -> None:
self._path = path
def read(self) -> bytes:
with open(self._path, "rb") as f:
return f.read()
def write(self, data: bytes) -> None:
with open(self._path, "wb") as f:
f.write(data)
class EncryptionDecorator:
def __init__(self, source: DataSource) -> None:
self._source = source
def read(self) -> bytes:
return decrypt(self._source.read())
def write(self, data: bytes) -> None:
self._source.write(encrypt(data))
class CompressionDecorator:
def __init__(self, source: DataSource) -> None:
self._source = source
def read(self) -> bytes:
return decompress(self._source.read())
def write(self, data: bytes) -> None:
self._source.write(compress(data))
# Stacking decorators:
source = CompressionDecorator(EncryptionDecorator(FileDataSource("/data/secrets.bin")))
When source.write(data) is called, CompressionDecorator compresses, passes to EncryptionDecorator which encrypts, passes to FileDataSource which writes. Each layer is independently testable and replaceable. This is fundamentally better than building a CompressedEncryptedFileDataSource class where all that logic lives in one place.
Python's function decorator syntax implements the same composition idea for callables:
import time
import functools
import logging
from typing import Callable, TypeVar, Any
F = TypeVar("F", bound=Callable[..., Any])
def timed(func: F) -> F:
@functools.wraps(func)
def wrapper(*args: Any, **kwargs: Any) -> Any:
start = time.perf_counter()
result = func(*args, **kwargs)
elapsed = time.perf_counter() - start
logging.info(f"{func.__name__} took {elapsed:.3f}s")
return result
return wrapper # type: ignore[return-value]
def retry(max_attempts: int = 3) -> Callable[[F], F]:
def decorator(func: F) -> F:
@functools.wraps(func)
def wrapper(*args: Any, **kwargs: Any) -> Any:
for attempt in range(max_attempts):
try:
return func(*args, **kwargs)
except Exception:
if attempt == max_attempts - 1:
raise
return wrapper # type: ignore[return-value]
return decorator
@timed
@retry(max_attempts=3)
def fetch_user(user_id: int) -> dict:
# ... network call ...
return {}
The stacking works identically to the object decorator pattern—timed wraps retry(3) which wraps fetch_user. Each layer adds behaviour without touching the original. Cross-cutting concerns like logging, timing, caching, and retry logic are classic decorator territory.
A practical note: always use functools.wraps. Without it, the wrapper steals the wrapped function's __name__ and __doc__, which ruins stack traces, debugging, and documentation. This is one of those things you only forget once, and then never again.
Template Method: Defining Skeletons with Overrideable Steps
Template Method is perhaps the most classically object-oriented pattern in this list—it genuinely requires inheritance to work. The idea: define the skeleton of an algorithm in a base class, mark specific steps as abstract or overrideable, and let subclasses fill in the steps without changing the overall structure.
A realistic example is a data pipeline. Every pipeline has the same structure: extract, validate, transform, load. What varies is how each step happens for different data sources.
from abc import ABC, abstractmethod
from typing import Any
class DataPipeline(ABC):
def run(self) -> None:
"""Template method — defines the invariant algorithm."""
raw = self.extract()
validated = self.validate(raw)
transformed = self.transform(validated)
self.load(transformed)
@abstractmethod
def extract(self) -> Any:
"""Pull raw data from the source."""
...
def validate(self, data: Any) -> Any:
"""Optional hook — subclasses can override."""
return data # Default: pass through
@abstractmethod
def transform(self, data: Any) -> Any:
"""Apply business transformations."""
...
@abstractmethod
def load(self, data: Any) -> None:
"""Persist the result."""
...
class SalesReportPipeline(DataPipeline):
def extract(self) -> list[dict]:
return fetch_from_crm()
def validate(self, data: list[dict]) -> list[dict]:
return [row for row in data if row.get("amount") is not None]
def transform(self, data: list[dict]) -> list[dict]:
return [{"date": row["date"], "revenue": row["amount"] * 1.1} for row in data]
def load(self, data: list[dict]) -> None:
insert_into_warehouse(data)
run() is the template method—it defines the invariant sequence. Subclasses cannot reorder the steps; they can only override what happens within each step. The base class retains control of the overall algorithm.
Template Method is worth knowing because it solves a real problem elegantly—but it is also one of the first patterns you should question. Inheritance creates tight coupling between the base class and its subclasses. If you can achieve the same result with Strategy (passing the steps as callables) or with a function that takes other functions as parameters, you will often get a more flexible design. The rule: use Template Method when the skeleton truly cannot vary and when the steps are tightly related to each other. If the steps are independent, consider Strategy instead.
Repository Pattern: A Structural Preview
The Repository pattern is not in the original GoF catalog—it comes from Domain-Driven Design—but it deserves a mention here because it is the data access pattern most aligned with clean architecture, and it is structurally similar to the Adapter.
The idea: your domain code should not know whether data lives in PostgreSQL, MongoDB, an in-memory dictionary, or a CSV file. You define a repository interface that speaks your domain's language (find_by_customer_id, save, list_active) and then write one concrete implementation per storage backend.
from typing import Protocol, Optional
from uuid import UUID
class Order: # Domain entity
...
class OrderRepository(Protocol):
def find_by_id(self, order_id: UUID) -> Optional[Order]: ...
def save(self, order: Order) -> None: ...
def list_pending(self) -> list[Order]: ...
class PostgresOrderRepository:
def __init__(self, session) -> None:
self._session = session
def find_by_id(self, order_id: UUID) -> Optional[Order]:
# SQLAlchemy query
...
def save(self, order: Order) -> None:
# SQLAlchemy upsert
...
def list_pending(self) -> list[Order]:
# SQLAlchemy query
...
class InMemoryOrderRepository:
def __init__(self) -> None:
self._store: dict[UUID, Order] = {}
def find_by_id(self, order_id: UUID) -> Optional[Order]:
return self._store.get(order_id)
def save(self, order: Order) -> None:
self._store[order.order_id] = order
def list_pending(self) -> list[Order]:
return [o for o in self._store.values() if o.is_pending()]
InMemoryOrderRepository is your test double, and it never touches a database. Sections 9 and 10 explore layered and hexagonal architecture in detail—the Repository pattern is the hinge between your domain and your data access layer, which is why it keeps appearing throughout clean architecture discussions.
Recognising Pattern Opportunities (and Cargo-Culting)
No section on patterns would be honest without a discussion of when not to use them.
The patterns in this section are solutions to forces. Adapter addresses interface mismatch. Strategy addresses conditional branching over algorithms. Observer addresses producer-consumer coupling. Factory addresses creation complexity. If the force is not present, the pattern is not needed—it is extra structure that adds indirection without adding value.
Here is the diagnostic question: would the code without this pattern cause a real problem? If your shipping calculation has exactly two options and zero chance of changing, a simple if/else is cleaner than a Strategy class. If your notification sending only ever goes to email, an Adapter to SendGrid is reasonable; abstracting it behind a Notifier Protocol is premature. You would be solving a problem you do not have yet, and that time investment rarely pays off.
The tell-tale signs of over-engineering:
- A class with one method and no state (write a function)
- An abstract base class with only one concrete subclass (remove the abstract class)
- A factory that constructs only one type of object (construct it directly)
- An Observer bus where there is only one publisher and one subscriber (just call the function)
- Any pattern applied "because we might need it later" with no concrete evidence of why
The patterns covered in this section—when applied to genuine forces—produce code that is easier to test, easier to extend, and easier to communicate. SOLID principles give you the underlying laws; patterns are named examples of those laws in action. The vocabulary is valuable. The elaborate class hierarchies are optional.
As you build the layered and hexagonal architectures covered in later sections, you will find these patterns recurring naturally—Adapter at the infrastructure boundary, Repository as the data access abstraction, Strategy for interchangeable business rules, Observer for domain events, Factory for constructing complex objects at startup. They are not a checklist; they are a toolkit. Reach for them when the problem they solve is the problem you have.
Only visible to you
Sign in to take notes.