Refactoring Toward Clean Architecture: A Worked Example
This is where theory meets the keyboard. We've spent the course building up a vocabulary—SOLID principles, Protocols, dependency injection, hexagonal architecture, the domain layer—and now we're going to use all of it on a piece of code that looks like it was written at 11pm on a deadline, because it was. That's the only honest way to do this.
The goal isn't to show you a beautiful "before" and a beautiful "after." The goal is to show you the process: the moments where you recognize a smell, the decisions you make, the places where you could go further but consciously choose not to. Architecture is a series of judgment calls, not a destination.
Let's begin.
The Starting Point: A Messy, Realistic Codebase
Here's our patient. It's a small tool that scrapes product prices from a fictional e-commerce API, stores them in a SQLite database, and emails a report to a list of stakeholders. Humble scope. Disastrous structure.
# price_tracker.py
import sqlite3
import smtplib
import requests
import json
from datetime import datetime
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
SMTP_HOST = "smtp.company.com"
SMTP_PORT = 587
SMTP_USER = "[email protected]"
SMTP_PASS = "hunter2"
DB_PATH = "/var/data/prices.db"
API_BASE = "https://api.shopexample.com/v2"
API_KEY = "sk-live-abc123"
RECIPIENTS = ["[email protected]", "[email protected]", "[email protected]"]
PRODUCT_IDS = [101, 202, 303, 404, 505]
def run():
conn = sqlite3.connect(DB_PATH)
conn.execute("""
CREATE TABLE IF NOT EXISTS price_records (
id INTEGER PRIMARY KEY AUTOINCREMENT,
product_id INTEGER,
name TEXT,
price REAL,
currency TEXT,
scraped_at TEXT
)
""")
conn.commit()
results = []
for pid in PRODUCT_IDS:
try:
resp = requests.get(
f"{API_BASE}/products/{pid}",
headers={"X-Api-Key": API_KEY},
timeout=10
)
resp.raise_for_status()
data = resp.json()
price = data["pricing"]["amount"]
currency = data["pricing"]["currency"]
name = data["name"]
conn.execute(
"INSERT INTO price_records (product_id, name, price, currency, scraped_at) "
"VALUES (?, ?, ?, ?, ?)",
(pid, name, price, currency, datetime.utcnow().isoformat())
)
conn.commit()
# Check if price dropped more than 10%
cursor = conn.execute(
"SELECT price FROM price_records WHERE product_id = ? "
"ORDER BY scraped_at DESC LIMIT 2",
(pid,)
)
rows = cursor.fetchall()
alert = False
pct_change = 0.0
if len(rows) == 2:
old_price = rows[1][0]
pct_change = ((price - old_price) / old_price) * 100
if pct_change <= -10:
alert = True
results.append({
"product_id": pid,
"name": name,
"price": price,
"currency": currency,
"pct_change": pct_change,
"alert": alert
})
except Exception as e:
print(f"Failed to fetch product {pid}: {e}")
results.append({
"product_id": pid,
"name": "UNKNOWN",
"price": 0.0,
"currency": "N/A",
"pct_change": 0.0,
"alert": False
})
# Build report
lines = [f"Price Report — {datetime.utcnow().strftime('%Y-%m-%d %H:%M')} UTC\n"]
lines.append("=" * 60)
for r in results:
flag = " ⚠️ PRICE DROP" if r["alert"] else ""
lines.append(
f"[{r['product_id']}] {r['name']}: "
f"{r['currency']} {r['price']:.2f} "
f"({r['pct_change']:+.1f}%){flag}"
)
report_body = "\n".join(lines)
# Send email
msg = MIMEMultipart()
msg["Subject"] = f"Price Tracker Report — {datetime.utcnow().strftime('%Y-%m-%d')}"
msg["From"] = SMTP_USER
msg["To"] = ", ".join(RECIPIENTS)
msg.attach(MIMEText(report_body, "plain"))
with smtplib.SMTP(SMTP_HOST, SMTP_PORT) as server:
server.starttls()
server.login(SMTP_USER, SMTP_PASS)
server.sendmail(SMTP_USER, RECIPIENTS, msg.as_string())
print("Done.")
if __name__ == "__main__":
run()
Go ahead and read it. It's not crazy. You can follow what it does. That's what makes code like this so insidious—it works, it's comprehensible in isolation, and therefore it accumulates. Six months from now there are 800 lines of it and nobody wants to touch it.
Diagnosing the Problems
Before we write a single line of new code, we diagnose. Refactoring without diagnosis is just rearranging furniture.
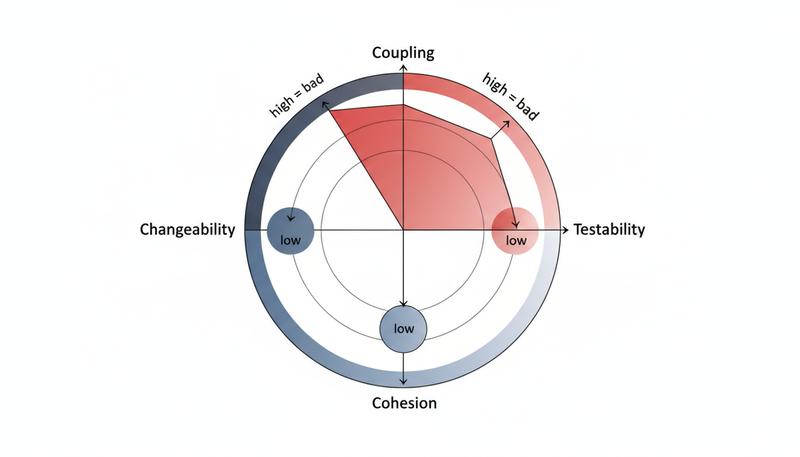
Coupling problems:
run()directly instantiates SQLite connections, HTTP sessions, and SMTP servers. You cannot swap any of them without editing this function.DB_PATH,SMTP_PASS,API_KEY—configuration is baked into module-level constants. Running this against a test database requires editing source code.- The
requests.get()call and the database write happen inside the same loop iteration. They're not just in the same function; they're interleaved, making it impossible to test one without the other.
Cohesion problems:
The run() function does at least five distinct things:
- HTTP fetching
- Data persistence
- Price change calculation (business logic!)
- Report formatting
- Email delivery
None of these things belong together. They change for entirely different reasons. The business analyst changes the price-drop threshold. The infrastructure team changes the SMTP server. The product team wants the report in Slack instead of email. Any of these changes require you to edit the same function.
Testability: zero. You cannot test any of this without actually hitting the API, writing to /var/data/prices.db, and sending email. That's not a test—that's an integration run that requires VPN access and makes your test suite expensive and flaky.
Naming problems: results, r, rows, data—these tell you nothing about domain meaning. alert is a boolean that doesn't communicate what kind of alert. pct_change isn't validated or encapsulated.
Let's map the coupling explicitly:
graph TD
RUN["run()"]
RUN --> HTTP["requests.get()"]
RUN --> DB["sqlite3 connection"]
RUN --> SMTP["smtplib.SMTP"]
RUN --> BIZ["Price drop logic"]
RUN --> FMT["Report formatting"]
HTTP --> API["External API"]
DB --> FS["Filesystem /var/data/prices.db"]
SMTP --> MAIL["SMTP server smtp.company.com"]
style RUN fill:#ff6b6b,color:#fff
style BIZ fill:#ffd93d
Everything flows into and out of run(). It's a God function—a single-function violation of the Single Responsibility Principle, and honestly the worst kind because it's not even obviously wrong.
The yellow node is the one that matters: the business logic (price drop detection) is buried inside infrastructure code. That's the core architectural sin this refactor will correct.
Step 1: Extract Functions and Name Things Properly
The first move is almost mechanical: pull the distinct behaviours out of run() into named functions. Don't redesign anything. Don't introduce classes. Don't think about abstractions. Just name things.
This step matters more than people think. Naming is diagnosis made explicit. When you struggle to name a function, it's because the function is doing too many things or operating at the wrong level of abstraction.
# Step 1: extracted functions, no other changes yet
def fetch_product(product_id: int) -> dict:
"""Fetch a single product's pricing data from the external API."""
resp = requests.get(
f"{API_BASE}/products/{product_id}",
headers={"X-Api-Key": API_KEY},
timeout=10
)
resp.raise_for_status()
return resp.json()
def save_price_record(conn, product_id: int, name: str, price: float, currency: str) -> None:
"""Persist a price observation to the database."""
conn.execute(
"INSERT INTO price_records (product_id, name, price, currency, scraped_at) "
"VALUES (?, ?, ?, ?, ?)",
(product_id, name, price, currency, datetime.utcnow().isoformat())
)
conn.commit()
def get_previous_price(conn, product_id: int) -> float | None:
"""Return the second-most-recent price for a product, or None."""
cursor = conn.execute(
"SELECT price FROM price_records WHERE product_id = ? "
"ORDER BY scraped_at DESC LIMIT 2",
(product_id,)
)
rows = cursor.fetchall()
return rows[1][0] if len(rows) == 2 else None
def calculate_price_change(current: float, previous: float | None) -> float:
"""Return percentage change from previous to current price."""
if previous is None or previous == 0:
return 0.0
return ((current - previous) / previous) * 100
def is_significant_drop(pct_change: float, threshold: float = -10.0) -> bool:
"""Return True if the price drop exceeds the threshold."""
return pct_change <= threshold
def format_report(results: list[dict]) -> str:
"""Render a list of price results as a plain-text report."""
lines = [f"Price Report — {datetime.utcnow().strftime('%Y-%m-%d %H:%M')} UTC\n"]
lines.append("=" * 60)
for r in results:
flag = " ⚠️ PRICE DROP" if r["alert"] else ""
lines.append(
f"[{r['product_id']}] {r['name']}: "
f"{r['currency']} {r['price']:.2f} "
f"({r['pct_change']:+.1f}%){flag}"
)
return "\n".join(lines)
def send_report_email(body: str) -> None:
"""Send the report to all configured recipients via SMTP."""
msg = MIMEMultipart()
msg["Subject"] = f"Price Tracker Report — {datetime.utcnow().strftime('%Y-%m-%d')}"
msg["From"] = SMTP_USER
msg["To"] = ", ".join(RECIPIENTS)
msg.attach(MIMEText(body, "plain"))
with smtplib.SMTP(SMTP_HOST, SMTP_PORT) as server:
server.starttls()
server.login(SMTP_USER, SMTP_PASS)
server.sendmail(SMTP_USER, RECIPIENTS, msg.as_string())
run() now becomes a thin coordinator. Already the business logic (calculate_price_change, is_significant_drop) is visually distinct from infrastructure concerns. We haven't changed what the code does—we've changed what we can see it does.
Notice is_significant_drop: that function has a default argument for threshold. That's the first sign of a design insight—the 10% threshold is a business rule, not a magic number, and it should be configurable. We'll come back to that.
Step 2: Group Into Classes with Clear Single Responsibilities
Functions are great, but right now fetch_product and save_price_record both implicitly depend on global state (the API credentials, the DB connection). We need to give that state somewhere to live. Classes with single responsibilities are the right tool here.
We'll also introduce a proper domain type. The dict bouncing through our code—{"product_id": ..., "price": ..., "alert": ...}—is shapeless. Let's give it a name.
from dataclasses import dataclass, field
from datetime import datetime
@dataclass(frozen=True)
class PriceRecord:
"""A single observed price for a product at a point in time."""
product_id: int
name: str
price: float
currency: str
observed_at: datetime = field(default_factory=datetime.utcnow)
@dataclass(frozen=True)
class PriceChangeResult:
"""The outcome of comparing a new price against historical data."""
record: PriceRecord
pct_change: float
is_significant_drop: bool
class ProductApiClient:
"""Fetches product data from the external pricing API."""
def __init__(self, base_url: str, api_key: str) -> None:
self._base_url = base_url
self._api_key = api_key
def fetch_product(self, product_id: int) -> PriceRecord:
resp = requests.get(
f"{self._base_url}/products/{product_id}",
headers={"X-Api-Key": self._api_key},
timeout=10
)
resp.raise_for_status()
data = resp.json()
return PriceRecord(
product_id=product_id,
name=data["name"],
price=data["pricing"]["amount"],
currency=data["pricing"]["currency"],
)
class PriceDatabase:
"""Stores and retrieves price records from SQLite."""
def __init__(self, db_path: str) -> None:
self._conn = sqlite3.connect(db_path)
self._ensure_schema()
def _ensure_schema(self) -> None:
self._conn.execute("""
CREATE TABLE IF NOT EXISTS price_records (
id INTEGER PRIMARY KEY AUTOINCREMENT,
product_id INTEGER,
name TEXT,
price REAL,
currency TEXT,
scraped_at TEXT
)
""")
self._conn.commit()
def save(self, record: PriceRecord) -> None:
self._conn.execute(
"INSERT INTO price_records (product_id, name, price, currency, scraped_at) "
"VALUES (?, ?, ?, ?, ?)",
(record.product_id, record.name, record.price,
record.currency, record.observed_at.isoformat())
)
self._conn.commit()
def get_previous_price(self, product_id: int) -> float | None:
cursor = self._conn.execute(
"SELECT price FROM price_records WHERE product_id = ? "
"ORDER BY scraped_at DESC LIMIT 2",
(product_id,)
)
rows = cursor.fetchall()
return rows[1][0] if len(rows) == 2 else None
class SmtpReportSender:
"""Delivers formatted reports via SMTP email."""
def __init__(self, host: str, port: int, user: str, password: str,
recipients: list[str]) -> None:
self._host = host
self._port = port
self._user = user
self._password = password
self._recipients = recipients
def send(self, body: str) -> None:
msg = MIMEMultipart()
msg["Subject"] = f"Price Tracker Report — {datetime.utcnow().strftime('%Y-%m-%d')}"
msg["From"] = self._user
msg["To"] = ", ".join(self._recipients)
msg.attach(MIMEText(body, "plain"))
with smtplib.SMTP(self._host, self._port) as server:
server.starttls()
server.login(self._user, self._password)
server.sendmail(self._user, self._recipients, msg.as_string())
We've made significant progress. PriceRecord and PriceChangeResult are frozen dataclasses—immutable value objects that communicate domain intent. Notice that PriceDatabase still talks directly to SQLite and ProductApiClient still talks directly to requests. We haven't solved the testability problem yet, but we've isolated where the problem lives.
The practical win from frozen=True on your domain dataclasses is underrated. You can hash them, use them as dict keys, and—most importantly—you can't accidentally mutate them in the middle of a pipeline and wonder why your report shows wrong numbers.
Step 3: Apply SOLID—Extract Interfaces with Protocols
Right now, PriceDatabase and ProductApiClient are concrete classes, and anything that uses them is tightly coupled to their implementations. If we want to swap SQLite for PostgreSQL, or mock the API for tests, we have to either monkey-patch or do surgery.
The answer is Python's Protocol—structural subtyping that lets us define the shape of a dependency without forcing an inheritance hierarchy. This is the Dependency Inversion Principle in its most Pythonic form.
from typing import Protocol
class ProductFetcher(Protocol):
"""Can retrieve a PriceRecord for a given product ID."""
def fetch_product(self, product_id: int) -> PriceRecord:
...
class PriceRepository(Protocol):
"""Can persist and retrieve price records."""
def save(self, record: PriceRecord) -> None:
...
def get_previous_price(self, product_id: int) -> float | None:
...
class ReportSender(Protocol):
"""Can deliver a formatted report string."""
def send(self, body: str) -> None:
...
Three protocols. Three narrow interfaces. Notice that ProductApiClient, PriceDatabase, and SmtpReportSender from Step 2 already satisfy these protocols—we didn't have to touch them. That's structural typing doing its job.
The Interface Segregation Principle is also visible here: we haven't created one giant InfrastructurePort protocol. Each protocol expresses exactly what a specific collaborator needs to do—no more, no less. A component that only sends reports doesn't need to know how to save records.
Step 4: Introduce Dependency Injection and a Composition Root
Now that we have protocols, we can build a service that depends on abstractions, not concretions. The business logic—coordinating fetches, saves, change calculations, and report delivery—belongs in a service class that receives its dependencies from outside.
class PriceTrackerService:
"""
Orchestrates the price-tracking workflow.
Pure coordinator: fetches prices, persists them, computes changes,
formats and sends the report. Has no direct infrastructure dependencies.
"""
def __init__(
self,
fetcher: ProductFetcher,
repository: PriceRepository,
sender: ReportSender,
drop_threshold_pct: float = -10.0,
) -> None:
self._fetcher = fetcher
self._repository = repository
self._sender = sender
self._drop_threshold_pct = drop_threshold_pct
def run(self, product_ids: list[int]) -> list[PriceChangeResult]:
results = []
for pid in product_ids:
try:
record = self._fetcher.fetch_product(pid)
previous_price = self._repository.get_previous_price(pid)
self._repository.save(record)
pct_change = self._compute_change(record.price, previous_price)
significant = pct_change <= self._drop_threshold_pct
results.append(PriceChangeResult(
record=record,
pct_change=pct_change,
is_significant_drop=significant,
))
except Exception as exc:
# Log and continue; a single failed product shouldn't abort the run
print(f"[WARN] Failed to process product {pid}: {exc}")
report = self._format_report(results)
self._sender.send(report)
return results
@staticmethod
def _compute_change(current: float, previous: float | None) -> float:
if previous is None or previous == 0:
return 0.0
return ((current - previous) / previous) * 100
@staticmethod
def _format_report(results: list[PriceChangeResult]) -> str:
lines = [f"Price Report — {datetime.utcnow().strftime('%Y-%m-%d %H:%M')} UTC\n"]
lines.append("=" * 60)
for r in results:
flag = " ⚠️ PRICE DROP" if r.is_significant_drop else ""
lines.append(
f"[{r.record.product_id}] {r.record.name}: "
f"{r.record.currency} {r.record.price:.2f} "
f"({r.pct_change:+.1f}%){flag}"
)
return "\n".join(lines)
Now the composition root—the one place in the entire application where concrete classes are instantiated and wired together. Following the pattern from hexagonal architecture's bootstrap layer, this lives at the entry point, not scattered through the codebase:
# main.py — the composition root
import os
from price_tracker.clients import ProductApiClient
from price_tracker.database import PriceDatabase
from price_tracker.email import SmtpReportSender
from price_tracker.service import PriceTrackerService
def main() -> None:
fetcher = ProductApiClient(
base_url=os.environ["API_BASE_URL"],
api_key=os.environ["API_KEY"],
)
repository = PriceDatabase(
db_path=os.environ.get("DB_PATH", "/var/data/prices.db")
)
sender = SmtpReportSender(
host=os.environ["SMTP_HOST"],
port=int(os.environ.get("SMTP_PORT", "587")),
user=os.environ["SMTP_USER"],
password=os.environ["SMTP_PASS"],
recipients=os.environ["REPORT_RECIPIENTS"].split(","),
)
service = PriceTrackerService(
fetcher=fetcher,
repository=repository,
sender=sender,
drop_threshold_pct=float(os.environ.get("DROP_THRESHOLD_PCT", "-10.0")),
)
product_ids = [int(x) for x in os.environ["PRODUCT_IDS"].split(",")]
service.run(product_ids)
if __name__ == "__main__":
main()
Configuration is now read from environment variables rather than hardcoded constants. No more SMTP_PASS = "hunter2". The composition root is the only place that knows about concrete classes—everything else talks to protocols. If you need to add a second sender (say, Slack), you add a new class that satisfies ReportSender and wire it in here. Nothing else changes.
Step 5: Separating the Domain from the Infrastructure
Let's look at the directory structure we've been building toward, because by now price_tracker.py has grown into something that deserves a package:
price_tracker/
├── __init__.py
├── domain/
│ ├── __init__.py
│ ├── models.py # PriceRecord, PriceChangeResult
│ └── ports.py # ProductFetcher, PriceRepository, ReportSender
├── application/
│ ├── __init__.py
│ └── service.py # PriceTrackerService
├── infrastructure/
│ ├── __init__.py
│ ├── api_client.py # ProductApiClient
│ ├── sqlite_repo.py # PriceDatabase
│ └── smtp_sender.py # SmtpReportSender
└── main.py # Composition root
This structure expresses an architectural truth: domain/ and application/ are the core. They import from nothing in infrastructure/. The infrastructure/ imports from domain/ (it needs the PriceRecord type) but not the other way around.
graph TD
MAIN["main.py\n(Composition Root)"]
APP["application/service.py\nPriceTrackerService"]
DOM["domain/models.py\nPriceRecord, PriceChangeResult"]
PORTS["domain/ports.py\nProtocols"]
INFRA_API["infrastructure/api_client.py"]
INFRA_DB["infrastructure/sqlite_repo.py"]
INFRA_SMTP["infrastructure/smtp_sender.py"]
MAIN --> APP
MAIN --> INFRA_API
MAIN --> INFRA_DB
MAIN --> INFRA_SMTP
APP --> PORTS
APP --> DOM
INFRA_API --> PORTS
INFRA_API --> DOM
INFRA_DB --> PORTS
INFRA_DB --> DOM
INFRA_SMTP --> PORTS
style DOM fill:#4ecdc4,color:#fff
style PORTS fill:#4ecdc4,color:#fff
style APP fill:#95e1d3
The arrows never point from domain/ outward to infrastructure/. That's the dependency rule in practice. Hexagonal architecture calls this "the domain is not aware of any ports or adapters"—and in Python, this manifests as import discipline. If you ever see from price_tracker.infrastructure import ... inside a domain module, a refactor is overdue.
The drop_threshold_pct parameter deserves a brief note here. In a richer domain, this would live inside the domain layer as a value object or a domain service with named constants. For a tool of this scope, a constructor parameter with a documented default is appropriate. Know your scope.
Step 6: Introduce a Repository to Abstract Data Access
Our PriceDatabase is concrete, but the PriceRepository protocol still leaves something on the table. The current get_previous_price method returns a raw float—that's fine for now, but it means the comparison logic has to happen outside the repository. Let's also think about what a real PriceDatabase looks like when we clean up the connection handling:
# infrastructure/sqlite_repo.py
import sqlite3
from contextlib import closing
from price_tracker.domain.models import PriceRecord
class PriceDatabase:
"""SQLite implementation of PriceRepository."""
def __init__(self, db_path: str) -> None:
self._db_path = db_path
self._ensure_schema()
def _connect(self) -> sqlite3.Connection:
conn = sqlite3.connect(self._db_path)
conn.row_factory = sqlite3.Row
return conn
def _ensure_schema(self) -> None:
with closing(self._connect()) as conn:
conn.execute("""
CREATE TABLE IF NOT EXISTS price_records (
id INTEGER PRIMARY KEY AUTOINCREMENT,
product_id INTEGER NOT NULL,
name TEXT NOT NULL,
price REAL NOT NULL,
currency TEXT NOT NULL,
scraped_at TEXT NOT NULL
)
""")
conn.execute(
"CREATE INDEX IF NOT EXISTS idx_product_scraped "
"ON price_records (product_id, scraped_at DESC)"
)
conn.commit()
def save(self, record: PriceRecord) -> None:
with closing(self._connect()) as conn:
conn.execute(
"INSERT INTO price_records "
"(product_id, name, price, currency, scraped_at) "
"VALUES (?, ?, ?, ?, ?)",
(record.product_id, record.name, record.price,
record.currency, record.observed_at.isoformat())
)
conn.commit()
def get_previous_price(self, product_id: int) -> float | None:
with closing(self._connect()) as conn:
cursor = conn.execute(
"SELECT price FROM price_records "
"WHERE product_id = ? "
"ORDER BY scraped_at DESC LIMIT 2",
(product_id,)
)
rows = cursor.fetchall()
# The most recent row is the one we *just* inserted,
# so the "previous" price is index 1.
return rows[1]["price"] if len(rows) == 2 else None
A few practitioner details worth highlighting here:
- We use
contextlib.closing()to ensure connections are always closed, even on exceptions. The original code held a single connection open for the entire run, which works fine until it doesn't. conn.row_factory = sqlite3.Rowgives us named column access (rows[1]["price"]instead ofrows[1][0])—a small thing that prevents an entire class of "wrong column index" bugs.- The index on
(product_id, scraped_at DESC)makes the "get previous price" query fast. The original code had no index and would do a full table scan.
We also have an important consideration: we're now opening a new connection per operation. For SQLite with a small tool like this, that's perfectly fine—SQLite connections are cheap. For a high-throughput service backed by PostgreSQL with connection pooling, this architecture would look different. The repository pattern abstracts exactly these decisions behind the PriceRepository protocol.
Step 7: Writing the Test Suite That Was Impossible Before
Here's the payoff. Because PriceTrackerService depends only on protocols, we can test it with pure Python fakes—no network, no disk, no SMTP server required.
# tests/test_service.py
import pytest
from datetime import datetime
from price_tracker.domain.models import PriceRecord, PriceChangeResult
from price_tracker.application.service import PriceTrackerService
# --- Fakes (not mocks: fakes have working implementations) ---
class FakeProductFetcher:
"""Returns pre-configured price records on demand."""
def __init__(self, products: dict[int, PriceRecord]) -> None:
self._products = products
self.fetched_ids: list[int] = []
def fetch_product(self, product_id: int) -> PriceRecord:
self.fetched_ids.append(product_id)
if product_id not in self._products:
raise ValueError(f"Product {product_id} not in fake catalog")
return self._products[product_id]
class FakePriceRepository:
"""In-memory repository; supports inspection after the fact."""
def __init__(self, history: dict[int, float] | None = None) -> None:
self._history: dict[int, float] = history or {}
self.saved: list[PriceRecord] = []
def save(self, record: PriceRecord) -> None:
self.saved.append(record)
def get_previous_price(self, product_id: int) -> float | None:
return self._history.get(product_id)
class FakeReportSender:
"""Captures sent reports for assertion."""
def __init__(self) -> None:
self.sent_reports: list[str] = []
def send(self, body: str) -> None:
self.sent_reports.append(body)
# --- Fixtures ---
def make_record(product_id: int, price: float, name: str = "Widget") -> PriceRecord:
return PriceRecord(
product_id=product_id,
name=name,
price=price,
currency="USD",
observed_at=datetime(2024, 6, 1, 12, 0, 0),
)
# --- Tests ---
class TestPriceTrackerService:
def test_new_product_has_zero_pct_change(self):
"""First observation for a product should show 0% change."""
fetcher = FakeProductFetcher({101: make_record(101, 50.0)})
repo = FakePriceRepository(history={}) # No history
sender = FakeReportSender()
service = PriceTrackerService(fetcher, repo, sender)
results = service.run([101])
assert len(results) == 1
assert results[0].pct_change == 0.0
assert not results[0].is_significant_drop
def test_detects_significant_price_drop(self):
"""A >10% drop should be flagged as significant."""
fetcher = FakeProductFetcher({202: make_record(202, 80.0)})
repo = FakePriceRepository(history={202: 100.0}) # Previous: 100.00
sender = FakeReportSender()
service = PriceTrackerService(fetcher, repo, sender, drop_threshold_pct=-10.0)
results = service.run([202])
assert results[0].pct_change == pytest.approx(-20.0)
assert results[0].is_significant_drop
def test_price_increase_is_not_flagged(self):
"""A price increase should not trigger a drop alert."""
fetcher = FakeProductFetcher({303: make_record(303, 120.0)})
repo = FakePriceRepository(history={303: 100.0})
sender = FakeReportSender()
service = PriceTrackerService(fetcher, repo, sender)
results = service.run([303])
assert results[0].pct_change == pytest.approx(20.0)
assert not results[0].is_significant_drop
def test_records_are_saved_after_fetch(self):
"""Each fetched product should be persisted to the repository."""
fetcher = FakeProductFetcher({
101: make_record(101, 50.0),
202: make_record(202, 75.0),
})
repo = FakePriceRepository()
sender = FakeReportSender()
service = PriceTrackerService(fetcher, repo, sender)
service.run([101, 202])
assert len(repo.saved) == 2
assert {r.product_id for r in repo.saved} == {101, 202}
def test_failed_product_does_not_abort_run(self):
"""A fetch error for one product should not prevent others from processing."""
fetcher = FakeProductFetcher({202: make_record(202, 75.0)})
# 101 is not in the fetcher — will raise ValueError
repo = FakePriceRepository()
sender = FakeReportSender()
service = PriceTrackerService(fetcher, repo, sender)
results = service.run([101, 202]) # 101 will fail silently
assert len(results) == 1
assert results[0].record.product_id == 202
def test_report_is_sent_once_per_run(self):
"""Exactly one report email should be dispatched per run()."""
fetcher = FakeProductFetcher({101: make_record(101, 50.0)})
repo = FakePriceRepository()
sender = FakeReportSender()
service = PriceTrackerService(fetcher, repo, sender)
service.run([101])
assert len(sender.sent_reports) == 1
def test_custom_threshold_is_respected(self):
"""A custom threshold of -5% should flag drops between 5% and 10%."""
fetcher = FakeProductFetcher({101: make_record(101, 93.0)})
repo = FakePriceRepository(history={101: 100.0}) # -7% drop
sender = FakeReportSender()
service = PriceTrackerService(fetcher, repo, sender, drop_threshold_pct=-5.0)
results = service.run([101])
assert results[0].is_significant_drop # Would NOT be flagged at default -10%
These tests run in milliseconds. They have no external dependencies. They're completely deterministic. And they test behaviour—not implementation details. Notice we use fakes (objects with working implementations) rather than mocks (objects with pre-programmed return values). Fakes are easier to read, easier to maintain, and they don't break when you refactor internal implementation details.
The test for failed products is particularly important. In the original code, the error-handling path was invisible—buried inside a try/except that printed to stdout and moved on. Now we can explicitly assert that a fetch failure for product 101 doesn't prevent product 202 from being processed. That behaviour is now documented in code.
Reviewing the Final Architecture
Let's step back and look at what we've built.
graph LR
subgraph "Infrastructure (Adapters)"
API_CLIENT["ProductApiClient\nHTTP → PriceRecord"]
SQLITE_REPO["PriceDatabase\nSQLite → PriceRecord"]
SMTP_SENDER["SmtpReportSender\nstr → Email"]
end
subgraph "Domain (Pure Python)"
MODELS["PriceRecord\nPriceChangeResult\n(frozen dataclasses)"]
PORTS["ProductFetcher\nPriceRepository\nReportSender\n(Protocols)"]
end
subgraph "Application"
SERVICE["PriceTrackerService\nOrchestrates workflow"]
end
MAIN["main.py\nComposition Root"]
MAIN --> SERVICE
MAIN --> API_CLIENT
MAIN --> SQLITE_REPO
MAIN --> SMTP_SENDER
SERVICE --> PORTS
SERVICE --> MODELS
API_CLIENT -.->|implements| PORTS
SQLITE_REPO -.->|implements| PORTS
SMTP_SENDER -.->|implements| PORTS
style MODELS fill:#4ecdc4,color:#fff
style PORTS fill:#4ecdc4,color:#fff
style SERVICE fill:#95e1d3
Let's run through the principles from the course and check our work:
Single Responsibility: Each class has one reason to change. ProductApiClient changes when the external API changes. PriceDatabase changes when the database schema changes. PriceTrackerService changes when the workflow logic changes.
Open/Closed: Want to add a Slack sender? Add SlackReportSender implementing ReportSender. Nothing else changes. Want to add a PostgreSQL repository? Same story.
Liskov Substitution: Our FakePriceRepository in the tests substitutes for PriceDatabase without any client code noticing. The fakes satisfy the protocols behaviorally, not just structurally.
Interface Segregation: Three narrow protocols instead of one wide interface. ReportSender doesn't carry baggage from PriceRepository.
Dependency Inversion: PriceTrackerService depends on ProductFetcher, PriceRepository, and ReportSender—abstractions. The concrete classes (ProductApiClient, etc.) depend on the same abstractions. High-level modules don't depend on low-level modules.
Hexagonal Architecture: The domain and application layers sit at the centre. Infrastructure adapters surround them. The composition root wires them together.
Compare the final state to the original:
| Concern | Before | After |
|---|---|---|
| Lines in main entry point | 80+ (everything) | ~25 (wiring only) |
| Can test without network/DB | No | Yes |
| Configuration in source code | Yes | No (env vars) |
| Domain logic visible | Buried | application/service.py |
| Adding a new sender | Edit run() |
Add a class, update main.py |
| Error handling | Silent print | Explicit, testable |
| Type safety | dict everywhere |
Typed dataclasses |
Knowing When to Stop: Enough Architecture for the Problem at Hand
Here's the honest part of the conversation.
This codebase is a small price-tracking script. It has five product IDs and sends one email. Is a layered hexagonal architecture with protocols and a composition root necessary?
No. Not for this scope. If this script runs once a day from a cron job and is maintained by one person who understands it completely, the extracted-functions version from Step 1 might be entirely sufficient. The full architecture is appropriate if:
- Multiple developers work on it
- You need to swap infrastructure components (e.g., migrate from SQLite to PostgreSQL)
- The business logic is expected to grow
- You need a test suite (and you always should eventually need a test suite)
- The tool becomes a service
The hexagonal architecture approach described at szymonmiks.pl makes this point explicitly: "We should use hexagonal architecture only where it's really needed." The gym management example in that article has a plain CRUD module (gym_classes) with no fancy structure—because it doesn't need it—and a richly structured module (gym_passes) because that's where the business logic lives and changes.
The skill—and this is what separates experienced practitioners from people who've read architecture books—is recognizing where in a codebase the complexity lives, and proportioning your structural investment accordingly. Over-engineering is a real cost. A five-file structure for a 50-line problem is not "good architecture"; it's anxiety expressed as abstraction.
Some heuristics that have served well in practice:
Stop when your abstractions outnumber your implementations. If you have four protocols and one concrete class, you're speculating about future variation that may never come.
Stop when tests become harder to write because of the architecture. Sometimes layering adds so much indirection that tests themselves become opaque. Tests that require three layers of fakes to test one business rule are a smell.
Stop when the next developer would be confused. The "bus factor" test: if you got hit by a bus tomorrow, could someone reasonable pick this up? A flat script with good names might be more maintainable than a sophisticated layered architecture that nobody else on the team understands.
Start when you feel the specific pain. The best time to add a repository pattern is when you need to swap databases, not when you imagine you might need to. The best time to add a protocol is when you're writing a second implementation of something. SOLID principles are tools for addressing specific forces—don't reach for them until you feel the force.
What we've done in this section is show you that the journey from spaghetti to clean architecture is a series of small, reversible steps, not a big-bang rewrite. Each step addressed a specific, nameable problem. Each step left the code in a better state than it found it. The test suite at Step 7 wasn't possible at Step 0—and that's the clearest sign that the refactor was worth doing.
Architecture is an ongoing conversation with your codebase. The voice of that conversation is code that reads clearly, fails loudly, and changes safely. Everything else is just vocabulary.
Only visible to you
Sign in to take notes.