The Domain Layer: Modelling Business Logic in Pure Python
If you've followed this course from the beginning, you've built up a vocabulary of tools: Protocols for structural typing, dataclasses for lightweight data containers, layered architecture for separating concerns, and hexagonal architecture for keeping your core logic isolated from the outside world. Now we're going to look at what actually lives at the centre of that hexagon — the domain layer — and how to write it well.
The domain layer is simultaneously the most important and the most abused layer in any application. It's where the money is made. It's where the business logic lives. And it's where, in too many codebases I've worked with, you find a thin collection of anemic data bags with no behaviour, all the real logic scattered across service classes and route handlers, and an ORM model masquerading as a domain object.
We're going to do better than that.
What the Domain Layer Is (and What It Is Not)
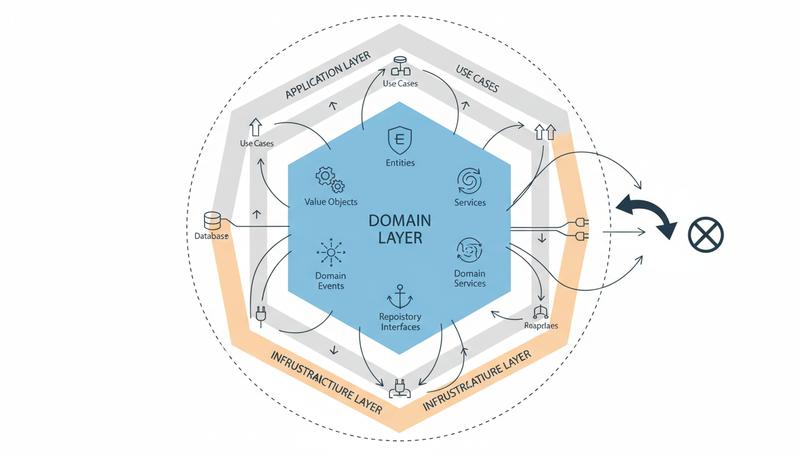
Let's start with a hard constraint: the domain layer has no external dependencies. Not Flask. Not SQLAlchemy. Not requests. Not boto3. Not celery. Nothing.
If you open a file in your domain layer and see an import from a framework or a database library, something has gone wrong. The domain layer is pure Python, full stop.
This sounds like an academic restriction until the first time you try to test a domain rule and discover you need a database connection to do it. At that point, the constraint starts to look like wisdom.
What the domain layer does contain:
- Entities — objects with identity and lifecycle (an
Order, aUser, aGymPass) - Value Objects — immutable descriptors with no identity (
Money,EmailAddress,DateRange) - Domain Services — stateless operations that span multiple entities
- Domain Events — records of things that happened (
OrderPlaced,PaymentFailed) - Domain Exceptions — failure cases expressed in business language
- Repository Interfaces — abstract contracts for fetching and storing domain objects
That last one is worth emphasising: the interface lives in the domain layer. The implementation lives in infrastructure. The domain knows that orders can be fetched by ID. It does not know that they're stored in a PostgreSQL table called orders with a composite index on customer_id and created_at.
Entities vs Value Objects: The Fundamental Distinction
Every domain model rests on two kinds of objects, and getting this distinction right saves you enormous amounts of confusion later.
An entity has identity. Two Order objects with the same customer ID and the same line items are not the same order if they have different order IDs. Identity persists across time and state changes. You track entities by their identity, not their attribute values.
A value object has no identity. Two Money objects representing £10.00 GBP are completely interchangeable. If you change a value object, you create a new one — you don't mutate the old one. Value objects are defined entirely by their attributes.
Python's dataclasses module gives us both, cleanly.
from dataclasses import dataclass, field
from decimal import Decimal
from uuid import UUID, uuid4
from enum import Enum, auto
# --- Value Objects ---
class Currency(Enum):
GBP = "GBP"
USD = "USD"
EUR = "EUR"
@dataclass(frozen=True)
class Money:
"""A value object. Frozen means immutable. Equality is by value."""
amount: Decimal
currency: Currency
def __post_init__(self) -> None:
if self.amount < Decimal("0"):
raise ValueError(f"Money amount cannot be negative: {self.amount}")
def add(self, other: "Money") -> "Money":
if self.currency != other.currency:
raise ValueError(
f"Cannot add {self.currency} and {other.currency}"
)
return Money(amount=self.amount + other.amount, currency=self.currency)
def multiply(self, factor: Decimal) -> "Money":
return Money(amount=self.amount * factor, currency=self.currency)
@dataclass(frozen=True)
class EmailAddress:
"""Another value object. Validates on construction."""
value: str
def __post_init__(self) -> None:
if "@" not in self.value or "." not in self.value.split("@")[-1]:
raise ValueError(f"Invalid email address: {self.value}")
def __str__(self) -> str:
return self.value
# --- Entity ---
class OrderStatus(Enum):
PENDING = auto()
CONFIRMED = auto()
SHIPPED = auto()
CANCELLED = auto()
@dataclass
class OrderLine:
"""Value object: an order line has no independent identity."""
product_id: UUID
quantity: int
unit_price: Money
@property
def subtotal(self) -> Money:
return self.unit_price.multiply(Decimal(self.quantity))
@dataclass
class Order:
"""An entity. Identity is the order_id, not the attributes."""
order_id: UUID
customer_email: EmailAddress
status: OrderStatus
lines: list[OrderLine] = field(default_factory=list)
@classmethod
def create(cls, customer_email: EmailAddress) -> "Order":
return cls(
order_id=uuid4(),
customer_email=customer_email,
status=OrderStatus.PENDING,
)
Notice a few things:
Money and EmailAddress use frozen=True, which makes them hashable and immutable. They'll behave correctly in sets and as dictionary keys, and you can never accidentally mutate them. Two Money(Decimal("10"), Currency.GBP) instances compare equal because dataclasses, by default, generate __eq__ based on attributes — which is exactly the semantics we want for value objects.
Order is not frozen. Orders change state. And its equality semantics should be identity-based — two Order instances with the same order_id are the same order, even if one has been updated. With mutable dataclasses, the default __eq__ compares all attributes, which is wrong for entities. You may want to override it:
@dataclass
class Order:
order_id: UUID
# ...
def __eq__(self, other: object) -> bool:
if not isinstance(other, Order):
return NotImplemented
return self.order_id == other.order_id
def __hash__(self) -> int:
return hash(self.order_id)
This is the part that trips people up when they first start building domain models in Python. The ORM approach — where identity is managed by the database — has trained us to think identity is automatic. In a clean domain model, you think about it explicitly.
Writing Business Rules as Methods
Here's the architectural choice that separates a rich domain model from an anemic one: business rules live on the objects they govern.
The anemic version looks like this:
# Don't do this
class OrderService:
def confirm_order(self, order: Order) -> None:
if order.status != OrderStatus.PENDING:
raise InvalidOperationError("Only pending orders can be confirmed")
if not order.lines:
raise InvalidOperationError("Cannot confirm an empty order")
order.status = OrderStatus.CONFIRMED
The logic is in a service class. The Order is a passive data bag. The service has to know about Order's internal rules.
The rich domain model version:
# Do this
class Order:
# ...
def confirm(self) -> None:
if self.status != OrderStatus.PENDING:
raise OrderAlreadyProcessed(
f"Order {self.order_id} cannot be confirmed: "
f"current status is {self.status.name}"
)
if not self.lines:
raise EmptyOrderError(
f"Order {self.order_id} has no lines and cannot be confirmed"
)
self.status = OrderStatus.CONFIRMED
def cancel(self) -> None:
if self.status in (OrderStatus.SHIPPED, OrderStatus.CANCELLED):
raise OrderAlreadyProcessed(
f"Order {self.order_id} cannot be cancelled from status "
f"{self.status.name}"
)
self.status = OrderStatus.CANCELLED
def add_line(self, product_id: UUID, quantity: int, unit_price: Money) -> None:
if self.status != OrderStatus.PENDING:
raise OrderAlreadyProcessed(
"Cannot add lines to a non-pending order"
)
if quantity <= 0:
raise ValueError(f"Quantity must be positive, got {quantity}")
self.lines.append(
OrderLine(
product_id=product_id,
quantity=quantity,
unit_price=unit_price,
)
)
@property
def total(self) -> Money:
if not self.lines:
raise EmptyOrderError("Cannot compute total of an empty order")
first, *rest = self.lines
return sum((line.subtotal for line in rest), start=first.subtotal)
Now Order speaks the business language. "Confirm this order." "Cancel it." "Add a line." The Order class is the authority on what's valid for an order. Application services, route handlers, and background tasks call these methods — they don't replicate the logic.
The practical benefit shows up in testing: you can test every business rule without a database, a web framework, or any mock whatsoever. Just create an Order and call a method.
def test_cannot_confirm_empty_order():
order = Order.create(customer_email=EmailAddress("[email protected]"))
with pytest.raises(EmptyOrderError):
order.confirm()
def test_cannot_add_line_to_confirmed_order():
order = Order.create(customer_email=EmailAddress("[email protected]"))
order.add_line(uuid4(), 1, Money(Decimal("10"), Currency.GBP))
order.confirm()
with pytest.raises(OrderAlreadyProcessed):
order.add_line(uuid4(), 2, Money(Decimal("5"), Currency.GBP))
Fast. Clean. No infrastructure. This is what hexagonal architecture enables when it says the domain layer is isolated from external dependencies — it makes this kind of testing trivially easy.
Domain Exceptions: Failure as a First-Class Citizen
I want to spend a moment on exceptions, because they're often an afterthought and they shouldn't be.
Raising a generic ValueError or RuntimeError when a business rule is violated is like sending a generic 500 error from a web API. Technically communicates something went wrong. Practically useless to anyone who has to handle it.
Domain exceptions are named, specific, and belong to the domain vocabulary:
class DomainError(Exception):
"""Base class for all domain errors. Catch this to handle any domain failure."""
pass
class OrderAlreadyProcessed(DomainError):
"""Raised when an operation is attempted on an order in an incompatible state."""
pass
class EmptyOrderError(DomainError):
"""Raised when an operation requires order lines but none exist."""
pass
class InsufficientInventoryError(DomainError):
"""Raised when a product cannot be allocated because stock is too low."""
def __init__(self, product_id: UUID, requested: int, available: int) -> None:
self.product_id = product_id
self.requested = requested
self.available = available
super().__init__(
f"Product {product_id}: requested {requested}, "
f"only {available} available"
)
class CurrencyMismatchError(DomainError):
"""Raised when arithmetic is attempted across incompatible currencies."""
pass
The hierarchy matters. DomainError as a base class lets application code catch all domain failures in one place for translation into HTTP errors or user messages, while still being specific enough to handle individual cases differently:
# In an application service or route handler:
try:
order.confirm()
except EmptyOrderError:
return {"error": "Please add items before confirming your order"}, 400
except OrderAlreadyProcessed as exc:
return {"error": str(exc)}, 409
except DomainError as exc:
# Catch-all for any domain failure we didn't anticipate specifically
logger.warning("Unexpected domain error: %s", exc)
return {"error": "Unable to process request"}, 422
Exceptions with structured attributes (like InsufficientInventoryError carrying product_id, requested, and available) give you the data you need to generate useful error messages without string-parsing exception messages — which is a habit you should break immediately if you have it.
The Repository Pattern: Hiding Persistence Behind a Collection
The Repository pattern is one of the most practically useful patterns in domain-driven design, and it maps naturally onto Python's Protocol system that we covered earlier in this course.
The core idea: your domain code shouldn't know how data is stored. An Order shouldn't know it comes from PostgreSQL. A User shouldn't know it's serialised to Redis. The domain just asks for objects by identity, saves them, and gets on with business.
A Repository provides a collection-like interface for a specific aggregate type:
from typing import Protocol
from uuid import UUID
class OrderRepository(Protocol):
def get(self, order_id: UUID) -> Order:
"""Retrieve an order by ID. Raises OrderNotFoundError if absent."""
...
def save(self, order: Order) -> None:
"""Persist an order (insert or update as appropriate)."""
...
def find_by_customer(self, email: EmailAddress) -> list[Order]:
"""Return all orders for a customer, newest first."""
...
That's the entire interface. Notice it raises a domain exception on not-found rather than returning None — this is a deliberate choice. None propagates silently and turns into AttributeError three stack frames later. A OrderNotFoundError fails loudly and immediately, with a message that tells you exactly what went wrong.
class OrderNotFoundError(DomainError):
def __init__(self, order_id: UUID) -> None:
self.order_id = order_id
super().__init__(f"Order {order_id} not found")
Whether to return None or raise is genuinely a judgment call in Python (the language happily supports both), but I've found that for domain repositories, raising is almost always right. The caller usually expects the object to exist — if it doesn't, that's an exceptional situation worth an exception.
graph TD
A[Application Service] -->|calls| B[OrderRepository Protocol]
B -->|implemented by| C[InMemoryOrderRepository]
B -->|implemented by| D[SQLAlchemyOrderRepository]
C -->|stores in| E[Python dict - tests]
D -->|queries| F[PostgreSQL - production]
A -->|works with| G[Order Entity]
G -->|raises| H[Domain Exceptions]
style B fill:#f0f4ff,stroke:#6366f1
style G fill:#f0fff4,stroke:#22c55e
style H fill:#fff0f0,stroke:#ef4444
Implementing the In-Memory Repository
The in-memory implementation is not a toy for tests — it's a design tool. Writing the in-memory version first forces you to think about what the interface actually needs before you get distracted by SQL. I've seen teams spend two days designing a repository interface that turned out to be completely wrong once they tried to use it in application code. Writing the in-memory version first costs twenty minutes and exposes the same problems.
from dataclasses import dataclass, field
import copy
class InMemoryOrderRepository:
"""
In-memory implementation for testing and development.
Stores deep copies to simulate the isolation that a real database provides —
you shouldn't be able to mutate a stored order by holding onto a reference.
"""
def __init__(self) -> None:
self._store: dict[UUID, Order] = {}
def get(self, order_id: UUID) -> Order:
try:
# Return a copy so callers can't mutate stored state accidentally
return copy.deepcopy(self._store[order_id])
except KeyError:
raise OrderNotFoundError(order_id)
def save(self, order: Order) -> None:
self._store[order.order_id] = copy.deepcopy(order)
def find_by_customer(self, email: EmailAddress) -> list[Order]:
return [
copy.deepcopy(o)
for o in self._store.values()
if o.customer_email == email
]
# Test helper — not part of the Protocol, deliberately
def count(self) -> int:
return len(self._store)
The deepcopy calls deserve explanation. A real database provides isolation by nature — when you load a row and modify the Python object, the database doesn't change until you explicitly commit. An in-memory dict doesn't do this. Without copying, you could do:
order = repo.get(some_id)
order.status = OrderStatus.CANCELLED
# The stored version is now also cancelled! No save() was called!
This is subtle and causes tests to pass when they shouldn't, because test state leaks between operations. The deep copy prevents this. Yes, it's slower — it doesn't matter for tests.
The SQLAlchemy Repository: Production Implementation
The production implementation is where interesting trade-offs appear. SQLAlchemy is the dominant Python ORM, and it has powerful features — but those features can easily leak into your domain if you let them.
The cleanest approach is to keep your domain classes completely free of SQLAlchemy, and map between them at the repository boundary. This is sometimes called the "classical mapping" or "data mapper" approach:
# infrastructure/repositories/sqlalchemy_order_repository.py
from sqlalchemy import Column, String, Enum as SAEnum, Numeric
from sqlalchemy.dialects.postgresql import UUID as PGUUID
from sqlalchemy.orm import Session, DeclarativeBase
from uuid import UUID
import json
class Base(DeclarativeBase):
pass
class OrderModel(Base):
"""SQLAlchemy model — lives in infrastructure, NOT in domain."""
__tablename__ = "orders"
order_id = Column(PGUUID(as_uuid=True), primary_key=True)
customer_email = Column(String(255), nullable=False, index=True)
status = Column(SAEnum(OrderStatus), nullable=False)
lines_json = Column(String, nullable=False, default="[]")
class SQLAlchemyOrderRepository:
def __init__(self, session: Session) -> None:
self._session = session
def get(self, order_id: UUID) -> Order:
model = self._session.get(OrderModel, order_id)
if model is None:
raise OrderNotFoundError(order_id)
return self._to_domain(model)
def save(self, order: Order) -> None:
existing = self._session.get(OrderModel, order.order_id)
if existing:
self._update_model(existing, order)
else:
model = self._to_model(order)
self._session.add(model)
def find_by_customer(self, email: EmailAddress) -> list[Order]:
models = (
self._session.query(OrderModel)
.filter_by(customer_email=str(email))
.all()
)
return [self._to_domain(m) for m in models]
def _to_domain(self, model: OrderModel) -> Order:
lines = [
OrderLine(
product_id=UUID(line["product_id"]),
quantity=line["quantity"],
unit_price=Money(
amount=Decimal(line["unit_price_amount"]),
currency=Currency(line["unit_price_currency"]),
),
)
for line in json.loads(model.lines_json)
]
return Order(
order_id=model.order_id,
customer_email=EmailAddress(model.customer_email),
status=model.status,
lines=lines,
)
def _to_model(self, order: Order) -> OrderModel:
return OrderModel(
order_id=order.order_id,
customer_email=str(order.customer_email),
status=order.status,
lines_json=self._serialise_lines(order.lines),
)
def _update_model(self, model: OrderModel, order: Order) -> None:
model.status = order.status
model.lines_json = self._serialise_lines(order.lines)
def _serialise_lines(self, lines: list[OrderLine]) -> str:
return json.dumps([
{
"product_id": str(line.product_id),
"quantity": line.quantity,
"unit_price_amount": str(line.unit_price.amount),
"unit_price_currency": line.unit_price.currency.value,
}
for line in lines
])
This is more code than the ORM-as-domain-model approach. That's the honest cost. You're writing explicit mappings in both directions. But consider what you've bought:
- Your
Orderdomain class has zero SQLAlchemy imports - You can change the database schema without touching domain logic
- You can swap SQLAlchemy for anything else (asyncpg, a document store, an API call) without changing the domain
- Your domain tests run at Python speed, not database speed
The mapping code is mechanical and tedious. It's also concentrated in one place and trivially testable. I'll take that trade every time over an anemic domain model or an ORM that's leaked into my business logic.
The ORM Leakage Problem
I want to be direct about what "ORM leakage" actually looks like in practice, because it's subtle and the damage accumulates slowly.
The first form is the lazy load trap. SQLAlchemy's lazy loading is convenient — you access order.customer and it fires a query. But this only works inside a database session. If you pass the order to a method that runs outside the session (say, a background worker or a serialisation step), you get a DetachedInstanceError. The object looks like a Python object but secretly requires a database connection. That's not a domain object; that's a database cursor wearing a trench coat.
The second form is identity map confusion. SQLAlchemy's session acts as an identity map — if you load the same order twice in the same session, you get the same Python object. This is helpful for ORM usage but makes domain reasoning strange. If your domain code assumes it can hold two independent copies of the same entity and mutate them separately, SQLAlchemy will surprise you.
The third form is the column-per-attribute trap. When your domain model is your ORM model, every domain attribute is a database column. Adding a derived property, an in-memory computed value, or a temporary flag to the domain object becomes awkward. You either add a spurious nullable column to the database or you fight the ORM.
None of these are unsolvable problems within an ORM-as-domain-model approach. But each one is a leak — a place where infrastructure concerns have entered the domain layer and started making demands.
Hexagonal architecture in Python explicitly addresses this: the domain layer "should not have any dependencies to the layers above it." The ORM is infrastructure. Keep it there.
The Unit of Work Pattern: Managing Transactions at the Boundary
Once you have a Repository, you immediately face a question: what happens when you need to modify two different aggregates atomically? You save the Order and you save the Inventory record. What if the second save fails?
The Unit of Work pattern answers this. It groups repository operations into a transaction boundary, and commits or rolls back together:
from typing import Protocol
from contextlib import AbstractContextManager
class UnitOfWork(Protocol):
orders: OrderRepository
def __enter__(self) -> "UnitOfWork":
...
def __exit__(self, *args: object) -> None:
...
def commit(self) -> None:
...
def rollback(self) -> None:
...
The SQLAlchemy implementation:
class SQLAlchemyUnitOfWork:
def __init__(self, session_factory: Callable[[], Session]) -> None:
self._session_factory = session_factory
def __enter__(self) -> "SQLAlchemyUnitOfWork":
self._session = self._session_factory()
self.orders = SQLAlchemyOrderRepository(self._session)
return self
def __exit__(self, exc_type: type | None, *args: object) -> None:
if exc_type:
self.rollback()
self._session.close()
def commit(self) -> None:
self._session.commit()
def rollback(self) -> None:
self._session.rollback()
And the in-memory version for tests:
class InMemoryUnitOfWork:
def __init__(self) -> None:
self.orders = InMemoryOrderRepository()
self.committed = False
def __enter__(self) -> "InMemoryUnitOfWork":
return self
def __exit__(self, exc_type: type | None, *args: object) -> None:
if exc_type:
self.rollback()
def commit(self) -> None:
self.committed = True
def rollback(self) -> None:
self.committed = False
Application code using the Unit of Work looks like this:
def confirm_order(order_id: UUID, uow: UnitOfWork) -> None:
with uow:
order = uow.orders.get(order_id)
order.confirm()
uow.orders.save(order)
uow.commit()
The application service doesn't know whether it's running against a real database or an in-memory fake. It uses the same code path in both cases. Testing confirm_order is now:
def test_confirm_order_updates_status():
uow = InMemoryUnitOfWork()
# Set up initial state
order = Order.create(EmailAddress("[email protected]"))
order.add_line(uuid4(), 2, Money(Decimal("15.00"), Currency.GBP))
with uow:
uow.orders.save(order)
uow.commit()
# Execute
confirm_order(order.order_id, uow)
# Assert
with uow:
saved_order = uow.orders.get(order.order_id)
assert saved_order.status == OrderStatus.CONFIRMED
No mocks. No patch. No database. Fast, deterministic, readable.
graph LR
A[Application Service] -->|uses| B[Unit of Work]
B -->|manages| C[Session / Transaction]
B -->|provides| D[OrderRepository]
D -->|loads/saves| E[Order Entity]
E -->|raises| F[Domain Exceptions]
B -->|commit or rollback| C
style B fill:#fef9c3,stroke:#ca8a04
style E fill:#f0fff4,stroke:#22c55e
The Anemic Domain Model: Recognising the Smell
We've mentioned the anemic domain model a few times in this course. Here, in the context of the domain layer, it deserves its own reckoning.
An anemic domain model is one where your domain objects are data bags — they have properties but no meaningful methods, no business rules, no validation beyond basic type checking. All the real logic lives in service classes that manipulate these passive objects.
The signs are familiar if you've worked in this kind of codebase:
# Anemic: the order does nothing
class Order:
def __init__(self):
self.id = None
self.status = None
self.lines = []
self.customer_email = None
# All logic in the service layer
class OrderService:
def confirm_order(self, order_id):
order = self.db.query(Order).filter_by(id=order_id).first()
if order.status != 'pending':
raise Exception("bad status")
if len(order.lines) == 0:
raise Exception("no lines")
order.status = 'confirmed'
self.db.commit()
def calculate_total(self, order):
total = 0
for line in order.lines:
total += line.quantity * line.unit_price
return total
def can_cancel(self, order):
return order.status in ('pending', 'confirmed')
You've seen this code. The OrderService has to know everything about Order's internal rules. The logic isn't reusable — to check if an order can be cancelled, you call order_service.can_cancel(order), which means you need an OrderService instance everywhere you need this check. Adding a new business rule means finding every service that touches orders and updating them.
Writing maintainable OOP code in Python is fundamentally about giving objects the right responsibilities. The Order class should be responsible for enforcing order-related rules, not the service layer.
The rich domain model alternative we've been building throughout this section doesn't have these problems. The rules live with the data they govern. The service layer orchestrates — it doesn't compute.
There is a legitimate exception: CRUD modules with no real business logic. If you're building a settings screen where users can update their display name, there are no business rules to encapsulate. An anemic model (or no domain model at all, just a DTO and a database write) is entirely appropriate. The hexagonal architecture example makes exactly this point — the gym classes module in that codebase uses no hexagonal architecture because it's pure CRUD. Using a rich domain model where there's no domain logic is just ceremony.
The problem emerges when developers apply CRUD thinking to genuinely complex domain logic and produce anemic models for things that have real rules, workflows, and invariants.
Putting It Together: A Working Domain Module
Here's what a reasonably complete domain module looks like in practice:
src/
orders/
domain/
__init__.py # exports the public domain surface
entities.py # Order, OrderLine
value_objects.py # Money, EmailAddress, Currency
exceptions.py # OrderNotFoundError, EmptyOrderError, etc.
repository.py # OrderRepository Protocol
services.py # domain services (if needed)
application/
use_cases.py # confirm_order, place_order, cancel_order
unit_of_work.py # UnitOfWork Protocol
infrastructure/
sqlalchemy_models.py # ORM models, separate from domain
repositories.py # SQLAlchemyOrderRepository, InMemoryOrderRepository
unit_of_work.py # SQLAlchemyUnitOfWork
The domain/ directory has no external dependencies. pip install the entire world into infrastructure/ if you like — the domain stays clean.
One practical note: the domain/__init__.py is worth thinking about. You can use it to create a clean public API for the domain module:
# orders/domain/__init__.py
from .entities import Order, OrderLine
from .value_objects import Money, EmailAddress, Currency
from .exceptions import (
DomainError,
OrderNotFoundError,
OrderAlreadyProcessed,
EmptyOrderError,
)
from .repository import OrderRepository
__all__ = [
"Order", "OrderLine",
"Money", "EmailAddress", "Currency",
"DomainError", "OrderNotFoundError", "OrderAlreadyProcessed", "EmptyOrderError",
"OrderRepository",
]
Consumers import from orders.domain, not from orders.domain.entities — the internal file structure is an implementation detail. This is the kind of small discipline that makes a codebase navigable six months later.
The Impedance Mismatch: A Practitioner's View
I want to end with something honest about the impedance mismatch between domain models and relational databases, because the textbook treatment understates how real and painful it is.
Relational databases think in tables, rows, and foreign keys. Domain models think in object graphs, behaviours, and invariants. When you have an Order with a list of OrderLine objects, the relational model sees two tables with a foreign key relationship. Every time you load an order, you're joining across tables. Every time you save it, you're figuring out which lines were added, which were removed, and which were modified.
SQLAlchemy handles this with change tracking — it watches your Python objects and generates the right SQL when you commit. This is genuinely useful, but it means your objects are observed. They carry SQLAlchemy instrumentation. They behave differently inside and outside a session. This is manageable with care, but it's not zero cost.
The approach I showed earlier — mapping between ORM models and domain objects explicitly in the repository — eliminates all of this at the cost of more mapping code. For complex domains with rich behaviour, I generally prefer it. For simpler domains, letting SQLAlchemy use its modern DeclarativeBase with dataclass integration can be a reasonable middle ground.
The pattern to avoid is cargo-culting one approach without thinking about the trade-offs for your specific situation. Some projects run perfectly well with SQLAlchemy models as their domain objects. Others genuinely need the separation. The question to ask is: "How often do my database schema requirements conflict with my domain model requirements?" If the answer is "rarely," the separation might be over-engineering. If the answer is "constantly," it's probably necessary.
That judgment — reading the forces on your specific codebase and choosing the tool that addresses them — is what this entire course has been building toward. The domain layer is just one more context in which you practice it.
Only visible to you
Sign in to take notes.